Préface
GNU/Linux est un système d’exploitation libre fonctionnant sur la base d’un noyau Linux, également appelé kernel Linux.
Linux est une implémentation libre du système UNIX et respecte les spécifications POSIX.
GNU/Linux est généralement distribué dans un ensemble cohérent de logiciels, assemblés autour du noyau Linux et prêt à être installé. Cet ensemble porte le nom de “Distribution”.
-
La plus ancienne des distributions est la distribution Slackware.
-
Les plus connues et utilisées sont les distributions Debian, RedHat et Arch, et servent de base pour d’autres distributions comme Ubuntu, CentOS, Fedora, Mageia ou Manjaro.
Chaque distribution présente des particularités et peut être développée pour répondre à des besoins très précis :
-
services d’infrastructure ;
-
pare-feu ;
-
serveur multimédia ;
-
serveur de stockage ;
-
etc.
La distribution présentée dans ces pages est la CentOS, qui est le pendant gratuit de la distribution RedHat. La distribution CentOS est particulièrement adaptée pour un usage sur des serveurs d’entreprises.
Crédits
Ce support de cours a été rédigé par les formateurs :
-
Patrick Finet ;
-
Antoine Le Morvan ;
-
Xavier Sauvignon ;
-
Nicolas Kovacs.
Licence
Formatux propose des supports de cours Linux libres de droits à destination des formateurs ou des personnes désireuses d’apprendre à administrer un système Linux en autodidacte.
Les supports de Formatux sont publiés sous licence Creative Commons-BY-SA et sous licence Art Libre. Vous êtes ainsi libre de copier, de diffuser et de transformer librement les œuvres dans le respect des droits de l’auteur.
BY : Paternité. Vous devez citer le nom de l’auteur original.
SA : Partage des Conditions Initiales à l’Identique.
-
Licence Creative Commons-BY-SA : https://creativecommons.org/licenses/by-sa/3.0/fr/
-
Licence Art Libre : http://artlibre.org/
Les documents de Formatux et leurs sources sont librement téléchargeables sur framagit :
Vous y trouverez la dernière version de ce document.
A partir des sources, vous pouvez générer votre support de formation personnalisé. Nous vous recommandons le logiciel AsciidocFX téléchargeable ici : http://asciidocfx.com/
Gestion des versions
| Version | Date | Observations |
|---|---|---|
1.0 |
Avril 2017 |
Version initiale. |
Introduction
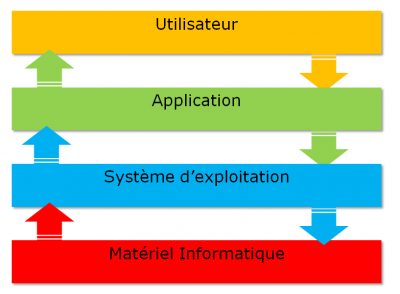
Qu’est-ce qu’un système d’exploitation ?
Linux est un système d’exploitation.
Un système d’exploitation est un ensemble de programmes permettant la gestion des ressources disponibles d’un ordinateur.
Parmi cette gestion des ressources, le système d’exploitation est amené à :
-
Gérer la mémoire physique ou virtuelle.
-
La mémoire physique est composée des barrettes de mémoires vives et de la mémoire cache du processeur, qui sert pour l’exécution des programmes.
-
La mémoire virtuelle est un emplacement sur le disque dur (la partition swap) qui permet de décharger la mémoire physique et de sauvegarder l’état en cours du système durant l’arrêt électrique de l’ordinateur (hibernation du système).
-
-
Intercepter les accès aux périphériques. Les logiciels ne sont que très rarement autorisés à accéder directement au matériel (à l’exception des cartes graphiques pour des besoins très spécifiques).
-
Offrir aux applications une gestion correcte des tâches. Le système d’exploitation est responsable de l’ordonnancement des processus pour l’occupation du processeur.
-
Protéger les fichiers contre tout accès non autorisé.
-
Collecter les informations sur les programmes utilisés ou en cours d’utilisation.
Généralités UNIX - GNU/Linux
Historique
UNIX
-
De 1964 à 1968 : MULTICS (MULTiplexed Information and Computing Service) est développé pour le compte du MIT, des laboratoires Bell Labs (AT&T) et de General Electric.
-
1969 : Après le retrait de Bell (1969) puis de General Electric du projet, deux développeurs (Ken Thompson et Dennis Ritchie), rejoints plus tard par Brian Kernighan, jugeant MULTICS trop complexe, lancent le développement d’UNIX (UNiplexed Information and Computing Service). À l’origine développé en assembleur, les concepteurs d’UNIX ont développé le langage B puis le langage C (1971) et totalement réécrit UNIX. Ayant été développé en 1970, la date de référence des systèmes UNIX/Linux est toujours fixée au 01 janvier 1970.
Le langage C fait toujours partie des langages de programmation les plus populaires aujourd’hui ! Langage de bas niveau, proche du matériel, il permet l’adaptation du système d’exploitation à toute architecture machine disposant d’un compilateur C.
UNIX est un système d’exploitation ouvert et évolutif ayant joué un rôle primordial dans l’histoire de l’informatique. Il a servi de base pour de nombreux autres systèmes : Linux, BSD, Mac OSX, etc.
UNIX est toujours d’actualité (HP-UX, AIX, Solaris, etc.)
Minix
-
1987 : Minix. A.S. Tanenbaum développe MINIX, un UNIX simplifié, pour enseigner les systèmes d’exploitation de façon simple. M. Tanenbaum rend disponible les sources de son système d’exploitation.
Linux

-
1991 : Linux. Un étudiant finlandais, Linus Torvalds, crée un système d’exploitation dédié à son ordinateur personnel et le nomme Linux. Il publie sa première version 0.02, sur le forum de discussion Usenet et d’autres développeurs viennent ainsi l’aider à améliorer son système. Le terme Linux est un jeu de mot entre le prénom du fondateur, Linus, et UNIX.
-
1993 : La distribution Debian est créée. Debian est une distribution non commerciale a gestion associative. À l’origine développée pour une utilisation sur des serveurs, elle est particulièrement bien adaptée à ce rôle, mais elle se veut être un système universel et donc utilisable également sur un ordinateur personnel. Debian est utilisée comme base pour de nombreuses autres distributions, comme Mint ou Ubuntu.
-
1994 : La distribution commerciale RedHat est créée par la société RedHat, qui est aujourd’hui le premier distributeur du système d’exploitation GNU/Linux. RedHat soutient la version communautaire Fedora et depuis peu la distribution libre CentOS.
-
1997 : L’environnement de bureau KDE est créé. Il est basé sur la bibliothèque de composants Qt et sur le langage de développement C++.
-
1999 : L’environnement de bureau Gnome est créé. Il est quant à lui basé sur la bibliothèque de composants GTK+.
-
2002 : La distribution Arch est créée. Sa particularité est d’être diffusée en Rolling Release (mise à jour en continue).
-
2004 : Ubuntu est créée par la société Canonical (Mark Shuttleworth). Elle se base sur Debian, mais regroupe des logiciels libres et privateurs.
Parts de marché
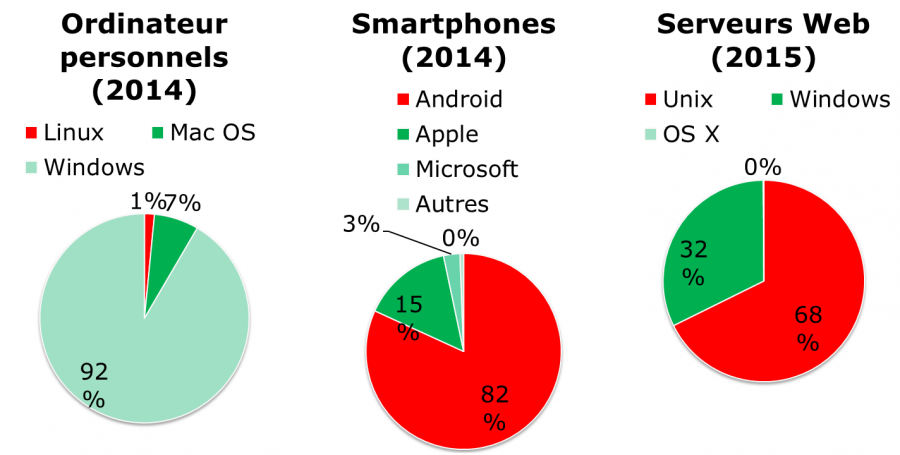
Linux est finalement encore peu connu du grand public, alors que ce dernier l’utilise régulièrement. En effet, Linux se cache dans les smartphones, les téléviseurs, les box internet, etc. Presque 70% des pages web servies dans le monde le sont par un serveur Linux ou UNIX !
Linux équipe un peu plus d'1,5% des ordinateurs personnels mais plus de 82% des smartphones. Android étant un système d’exploitation dont le kernel est un Linux.
Architecture
-
Le noyau (ou kernel) est le premier composant logiciel.
-
Il est le cœur du système UNIX.
-
C’est lui qui gère les ressources matérielles du système.
-
Les autres composants logiciels passent obligatoirement par lui pour accéder au matériel.
-
-
Le Shell est un utilitaire qui interprète les commandes de l’utilisateur et assure leur exécution.
-
Principaux shell : Bourne shell, C shell, Korn shell et Bourne Again shell (bash).
-
-
Les applications regroupent les programmes utilisateurs comme :
-
le navigateur internet ;
-
le traitement de texte ;
-
…
-
Multitâche
Linux fait partie de la famille des systèmes d’exploitation à temps partagé. Il partage le temps d’utilisation processus entre plusieurs programmes, passant de l’un à l’autre de façon transparente pour l’utilisateur. Cela implique :
-
exécution simultanée de plusieurs programmes ;
-
distribution du temps CPU par l’ordonnanceur ;
-
réduction des problèmes dus à une application défaillante ;
-
diminution des performances lorsqu’il y a trop de programmes lancés.
Multiutilisateurs
La finalité de Multics était de permettre à plusieurs utilisateurs de travailler à partir de plusieurs terminaux (écran et clavier) sur un seul ordinateur (très coûteux à l’époque). Linux étant un descendant de ce système d’exploitation, il a gardé cette capacité à pouvoir fonctionner avec plusieurs utilisateurs simultanément et en toute indépendance, chacun ayant son compte utilisateur, son espace de mémoire et ses droits d’accès aux fichiers et aux logiciels.
Multiprocesseur
Linux est capable de travailler avec des ordinateurs multiprocesseurs ou avec des processeurs multicœurs.
Multiplateforme
Linux est écrit en langage de haut niveau pouvant s’adapter à différents types de plate-formes lors de la compilation. Il fonctionne donc sur :
-
les ordinateurs des particuliers (le PC ou l’ordinateur portable) ;
-
les serveurs (données, applications,…) ;
-
les ordinateurs portables (les smartphones ou les tablettes) ;
-
les systèmes embarqués (ordinateur de voiture) ;
-
les éléments actifs des réseaux (routeurs, commutateurs) ;
-
les appareils ménagers (téléviseurs, réfrigérateurs,…).
Ouvert
Linux se base sur des standards reconnus (posix, TCP/IP, NFS, Samba …) permettant de partager des données et des services avec d’autres systèmes d’applications.
La philosophie UNIX
-
Tout est fichier.
-
Portabilité.
-
Ne faire qu’une seule chose et la faire bien.
-
KISS : Keep It Simple and Stupid.
-
“UNIX est simple, il faut juste être un génie pour comprendre sa simplicité” (Dennis Ritchie)
-
“UNIX est convivial. Cependant UNIX ne précise pas vraiment avec qui.” (Steven King)
Les distributions GNU/LINUX
Une distribution Linux est un ensemble cohérent de logiciels assemblés autour du noyau Linux et prêt à être installé. Il existe des distributions associatives ou communautaires (Debian, CentOS) ou commerciales (RedHat, Ubuntu).
Chaque distribution propose un ou plusieurs environnements de bureau, fournit un ensemble de logiciels pré-installés et une logithèque de logiciels supplémentaires. Des options de configuration (options du noyau ou des services par exemple) sont propres à chacune.
Ce principe permet d’avoir des distributions orientées débutants (Ubuntu, Linux Mint …) ou d’une approche plus complexe (Gentoo, Arch), destinées à faire du serveur (Debian, RedHat, …) ou dédiées à des postes de travail.
Les environnements de bureaux
Les environnements graphiques sont nombreux : Gnome, KDE, LXDE, XFCE, etc. Il y en a pour tous les goûts, et leurs ergonomies n’ont pas à rougir de ce que l’on peut retrouver sur les systèmes Microsoft ou Apple !
Alors pourquoi si peu d’engouement pour Linux, alors qu’il n'existe pas (ou presque pas) de virus pour ce système ? Parce que tous les éditeurs (Adobe) ou constructeur (NVidia) ne jouent pas le jeu du libre et ne fournissent pas de version de leurs logiciels ou de leurs drivers pour GNU/Linux. Trop peu de jeux également sont (mais plus pour longtemps) distribués sous Linux.
La donne changera-t-elle avec l’arrivée de la steam-box qui fonctionne elle aussi sous Linux ?
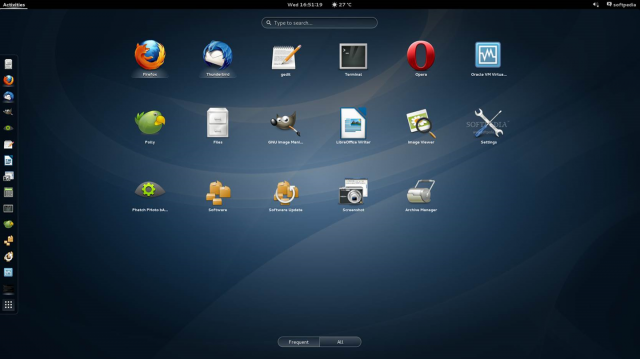
L’environnement de bureau Gnome 3 n’utilise plus le concept de Bureau mais celui de Gnome Shell (à ne pas confondre avec le shell de la ligne de commande). Il sert à la fois de bureau, de tableau de bord, de zone de notification et de sélecteur de fenêtre. L’environnement de bureau Gnome se base sur la bibliothèque de composants GTK+.
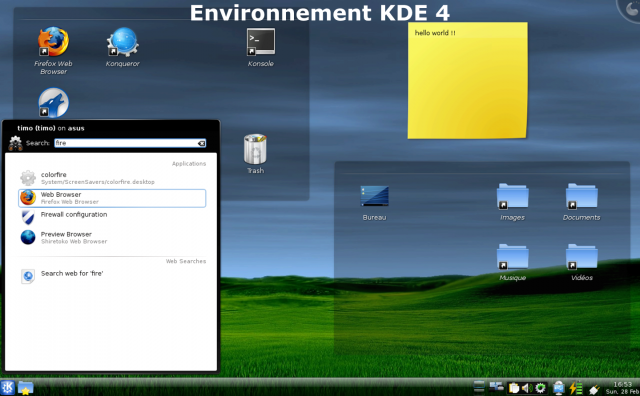
L’environnement de bureau KDE se base sur la bibliothèque de composants Qt.
Il est traditionnellement plus conseillé aux utilisateurs venant d’un monde Windows.

Libre / Open source
Un utilisateur de système d’exploitation Microsoft ou Mac doit s’affranchir d’une licence d’utilisation du système d’exploitation. Cette licence a un coût, même s’il est généralement transparent (le prix de la licence étant inclus dans le prix de l’ordinateur).
Dans le monde GNU/Linux, le mouvement du Libre permet de fournir des distributions gratuites.
Libre ne veut pas dire gratuit !
Open source : les codes sources sont disponibles, il est donc possible de les consulter, de les modifier et de le diffuser.
Licence GPL (General Public License)
La Licence GPL garantit à l’auteur d’un logiciel sa propriété intellectuelle, mais autorise la modification, la rediffusion ou la revente de logiciels par des tiers, sous condition que les codes sources soient fournis avec le logiciel. La licence GPL est la licence issue du projet GNU (GNU is Not UNIX), projet déterminant dans la création de Linux.
Elle implique :
-
la liberté d’exécuter le programme, pour tous les usages ;
-
la liberté d’étudier le fonctionnement du programme et de l’adapter aux besoins ;
-
la liberté de redistribuer des copies ;
-
la liberté d’améliorer le programme et de publier vos améliorations, pour en faire profiter toute la communauté.
Par contre, même des produits sous licences GPL peuvent être payants. Ce n’est pas le produit en lui-même mais la garantie qu’une équipe de développeurs continue à travailler dessus pour le faire évoluer et dépanner les erreurs, voire fournir un soutien aux utilisateurs.
Les domaines d’emploi
Une distribution Linux excelle pour :
-
Un serveur : HTTP, messagerie, groupware, partage de fichiers, etc.
-
La sécurité : Passerelle, pare-feu, routeur, proxy, etc.
-
Ordinateur central : Banques, assurances, industrie, etc.
-
Système embarqué : Routeurs, Box Internet, SmartTV, etc.
Linux est un choix adapté pour l’hébergement de base de données ou de sites web, ou comme serveur de messagerie, DNS, pare-feu. Bref Linux peut à peu près tout faire, ce qui explique la quantité de distributions spécifiques.
Shell
Généralités
Le shell, interface de commandes en français, permet aux utilisateurs d’envoyer des ordres au système d’exploitation. Il est moins visible aujourd’hui, depuis la mise en place des interfaces graphiques, mais reste un moyen privilégié sur les systèmes Linux qui ne possèdent pas tous des interfaces graphiques et dont les services ne possèdent pas toujours une interface de réglage.
Il offre un véritable langage de programmation comprenant les structures classiques : boucles, alternatives et les constituants courants : variables, passage de paramètres, sous-programmes. Il permet donc la création de scripts pour automatiser certaines actions (sauvegardes, création d’utilisateurs, surveillance du système,…).
Il existe plusieurs types de Shell disponibles et configurables sur une plate-forme ou selon le choix préférentiel de l’utilisateur :
-
sh, le shell aux normes POSIX ;
-
csh, shell orienté commandes en C ;
-
bash, Bourne Again Shell, shell de Linux.
-
etc, …
Fonctionnalités
-
Exécution de commandes (vérifie la commande passée et l’exécute) ;
-
Redirections Entrées/Sorties (renvoi des données dans un fichier au lieu de l’inscrire sur l’écran) ;
-
Processus de connexion (gère la connexion de l’utilisateur) ;
-
Langage de programmation interprété (permettant la création de scripts) ;
-
Variables d’environnement (accès aux informations propres au système en cours de fonctionnement).
Principe
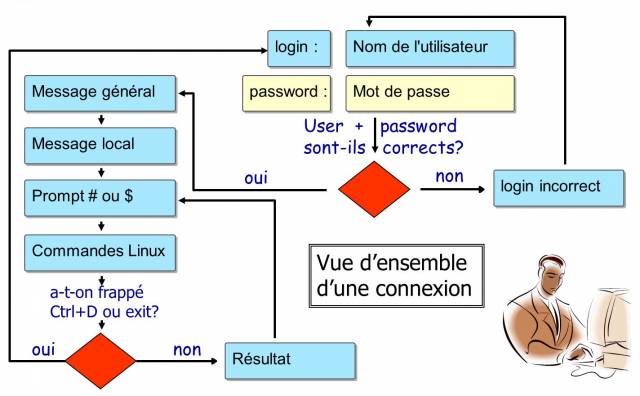
Commandes pour utilisateurs Linux
Généralités
Les systèmes Linux actuels possèdent des utilitaires graphiques dédiés au travail d’un administrateur. Toutefois, il est important d’être capable d’utiliser l’interface en mode ligne de commandes et cela pour plusieurs raisons :
-
La majorité des commandes du système sont communes à toutes les distributions Linux, ce qui n’est pas le cas des outils graphiques.
-
Il peut arriver que le système ne démarre plus correctement mais qu’un interpréteur de commandes de secours reste accessible.
-
L’administration à distance se fait en ligne de commandes avec un terminal SSH.
-
Afin de préserver les ressources du serveur, l’interface graphique n’est soit pas installée, soit lancée à la demande.
-
L’administration se fait par des scripts.
L’apprentissage de ces commandes permet à l’administrateur de se connecter à un terminal Linux, de gérer ses ressources, ses fichiers, d’identifier la station, le terminal et les utilisateurs connectés, etc.
Les utilisateurs
L’utilisateur du système Linux est défini (dans le fichier /etc/passwd) par :
-
un nom de connexion, plus communément appelé « login », ne contenant pas d’espace ;
-
un identifiant numérique : UID (User Identifier) ;
-
un identifiant de groupe : GID (Group Identifier) ;
-
un mot de passe, qui sera chiffré avant d’être stocké ;
-
un interpréteur de commandes, un shell, qui peut être différent d’un utilisateur à l’autre ;
-
un répertoire de connexion, le home directory ;
-
une invite de commande, ou prompt de connexion, qui sera symbolisée par un
#pour les administrateurs et un$pour les autres utilisateurs.
En fonction de la politique de sécurité mise en œuvre sur le système, le mot de passe devra comporter un certain nombre de caractères et respecter des exigences de complexité.
Parmi les interpréteurs de commandes existants, le Bourne Again Shell (/bin/bash) est celui qui est le plus fréquemment utilisé. Il est affecté par défaut aux nouveaux utilisateurs. Pour diverses raisons, des utilisateurs avancés de Linux choisiront des interpréteurs de commandes alternatifs parmi le Korn Shell (ksh), le C Shell (csh), etc.
Le répertoire de connexion de l’utilisateur est par convention stocké dans le répertoire /home du poste de travail. Il contiendra les données personnelles de l’utilisateur. Par défaut, à la connexion, le répertoire de connexion est sélectionné comme répertoire courant.
Une installation type poste de travail (avec interface graphique) démarre cette interface sur le terminal 1. Linux étant multi-utilisateurs, il est possible de connecter plusieurs utilisateurs plusieurs fois, sur des terminaux physiques (TTY) ou virtuels (PTS) différents. Les terminaux virtuels sont disponibles au sein d’un environnement graphique. Un utilisateur bascule d’un terminal physique à l’autre à l’aide des touches Alt+Fx depuis la ligne de commandes ou à l’aide des touches Ctrl+Alt+Fx.
Le shell
Une fois que l’utilisateur est connecté sur une console, le shell affiche l’invite de commandes (prompt). Il se comporte ensuite comme une boucle infinie, à chaque saisie d’instruction :
-
affichage de l’invite de commande ;
-
lecture de la commande ;
-
analyse de la syntaxe ;
-
substitution des caractères spéciaux ;
-
exécution de la commande ;
-
affichage de l’invite de commande ;
-
etc.
La séquence de touche Ctrl+C permet d’interrompre une commande en cours d’exécution.
L’utilisation d’une commande respecte généralement cette séquence :
commande [option(s)] [arguments(s)]Le nom de la commande est toujours en minuscules.
Un espace sépare chaque élément.
Les options courtes commencent par un tiret (-l), alors que les options longues
commencent par deux tirets (--list). Un double tiret (--) indique la fin de la liste d’options. Il est possible de regrouper certaines options courtes :
$ ls -l -i -aest équivalent à :
$ ls -liaIl peut bien entendu y avoir plusieurs arguments après une option :
$ ls -lia /etc /home /varDans la littérature, le terme « option » est équivalent au terme « paramètre », plus utilisé dans le domaine de la programmation. Le côté optionnel d’une option ou d’un argument est symbolisé en le mettant entre crochets [ et ]. Lorsque plusieurs options sont possibles, une barre verticale appelée « pipe » les sépare [a|e|i].
Les commandes générales
Les commandes man et whatis
Il est impossible pour un administrateur, quel que soit son niveau, de connaître toutes les commandes et options dans les moindres détails. Une commande a été spécialement conçue pour accéder en ligne de commandes à un ensemble d’aides, sous forme d’un manuel : la commande man (« le man est ton ami »).
Ce manuel est divisé en 8 sections, regroupant les informations par thèmes, la section par défaut étant la section 1 :
-
Commandes utilisateurs ;
-
Appels système ;
-
Fonctions de bibliothèque C ;
-
Périphériques et fichiers spéciaux ;
-
Formats de fichiers ;
-
Jeux ;
-
Divers ;
-
Outils d’administration système et démons.
Des informations sur chaque section sont accessibles en saisissant man x intro, x indiquant le numéro de section.
La commande :
$ man passwdinformera l’administrateur sur la commande passwd, ses options, etc. Alors qu’un :
$ man 5 passwdl’informera sur les fichiers en relations avec la commande.
Toutes les pages du manuel ne sont pas traduites de l’anglais. Elles sont toutefois généralement très précises et fournissent toutes les informations utiles. La syntaxe utilisée et le découpage peuvent dérouter l’administrateur débutant, mais avec de la pratique, l’administrateur y retrouvera rapidement l’information qu’il recherche.
La navigation dans le manuel se fait avec les flèches ↑ et ↓. Le manuel se quitte en appuyant sur la touche q.
La commande whatis permet de faire une recherche par mot clef au sein des pages de manuel :
$ whatis clearLa commande shutdown
La commande shutdown permet de stopper électriquement, immédiatement ou après un certain laps de temps, un serveur Linux.
[root]# shutdown [-h] [-r] heure [message]L’heure d’arrêt est à indiquer au format hh:mm pour une heure précise, ou +mm pour un délai en minutes.
Pour forcer un arrêt immédiat, le mot now remplacera l’heure. Dans ce cas, le message optionnel n’est pas envoyé aux autres utilisateurs du système.
-
Exemples :
[root]# shutdown -h 0:30 "Arrêt du serveur à 0h30"
[root]# shutdown -r +5-
Options :
| Options | Observations |
|---|---|
|
Arrête le système électriquement |
|
Redémarre le système |
La commande history
La commande history permet d’afficher l’historique des commandes qui ont été saisies par l’utilisateur.
Les commandes sont mémorisées dans le fichier .bash_history du répertoire de connexion de l’utilisateur.
$ history
147 man ls
148 man historyOptions |
Commentaires |
|
L’option |
|
L’option |
-
Manipuler l’historique :
Pour manipuler l’historique, des commandes permettent depuis l’invite de commandes de :
| Touches | Fonction |
|---|---|
|
Rappeler la dernière commande passée. |
|
Rappeler la commande par son numéro dans la liste. |
|
Rappeler la commande la plus récente commençant par la chaîne de caractères. |
|
Remonter l’historique des commandes. |
|
Redescendre l’historique des commandes. |
L’auto-complétion
L’auto-complétion est également d’une aide précieuse.
-
Elle permet de compléter les commandes, les chemins saisis ou les noms de fichiers.
-
Un appui sur la touche TAB complète la saisie dans le cas d’une seule solution.
-
Sinon, il faudra faire un deuxième appui pour obtenir la liste des possibilités.
Si un double appui sur la touche TAB ne provoque aucune réaction de la part du système, c’est qu’il n’existe aucune solution à la complétion en cours.
Affichage et identification
La commande clear
La commande clear permet d’effacer le contenu de l’écran du terminal. En réalité, pour être plus précis, elle permet de décaler l’affichage de sorte que l’invite de commandes se retrouve en haut de l’écran sur la première ligne.
Dans un terminal, l’affichage sera définitivement masqué tandis que dans une interface graphique, un ascenseur permettra de remonter dans l’historique du terminal virtuel.
La commande echo
La commande echo permet d’afficher une chaîne de caractères.
Cette commande est plus particulièrement utilisée dans les scripts d’administration pour informer l’utilisateur pendant l’exécution.
L’option -n permet de ne pas revenir à la ligne après avoir affiché le texte (ce qui est le comportement par défaut de la commande).
Pour diverses raisons, le développeur du script peut être amené à utiliser des séquences spéciales (commençant par un caractère \). Dans ce cas, l’option -e sera stipulée, permettant l’interprétation des séquences.
Parmi les séquences fréquemment utilisées, nous citerons :
| Séquence | Résultat |
|---|---|
|
Émet un bip sonore |
|
Retour en arrière |
|
Ajoute un saut de ligne |
|
Ajoute une tabulation horizontale |
|
Ajoute une tabulation verticale |
La commande date
La commande date permet d’afficher la date et l’heure. La commande respecte la syntaxe suivante :
date [-d AAAAMMJJ] [format]Exemples :
$ date
mer. Avril 17 16:46:53 CEST 2013
$ date -d 20150729 +%j
210Dans ce dernier exemple, l’option -d affiche une date donnée. L’option +%j formate cette date pour n’afficher que le quantième.
|
Le format d’une date peut changer suivant la valeur de la langue définie dans la variable d’environnement |
L’affichage de la date peut suivre les formats suivants :
| Option | Format |
|---|---|
|
Nom complet du jour |
|
Nom complet du mois |
|
Affichage complet de la date |
|
Numéro du jour |
|
Date au format |
|
Année |
|
Heure |
|
Quantième du jour |
|
Numéro du mois |
|
Minute |
|
Heure au format |
|
Secondes depuis le 1er janvier 1970 |
|
Heure au format |
|
Jour de la semaine ( |
|
Numéro de la semaine |
|
Date au format |
La commande date permet également de modifier la date et l’heure système. Dans ce cas, l’option -s sera utilisée.
[root]# date -s "2013-04-17 10:19"
jeu. Avril 17 10:19:00 CEST 2013Le format à respecter pour l’argument suivant l’option -s est celui-ci :
date -s "[AA]AA-MM-JJ hh:mm:[ss]"Les commandes id, who et whoami
La commande id affiche le nom de l’utilisateur courant et ses groupes ou ceux d’un utilisateur, si le login de celui-ci est fourni comme argument.
$ id util1
uid=501(util1) gid=501(group1) groups=501(group1),502(group2)Les options -g, -G, -n et -u affichent respectivement le GID du groupe principal, les GID des groupes secondaires, les noms au lieu des identifiants numériques et l’UID de l’utilisateur.
La commande whoami affiche le login de l’utilisateur courant.
La commande who seule affiche le nom des utilisateurs connectés :
$ who
stagiaire tty1 2014-09-15 10:30
root pts/0 2014-09-15 10:31Linux étant multi-utilisateurs, il est probable que plusieurs sessions soient ouvertes sur la même station, que ce soit physiquement ou à travers le réseau. Il est intéressant de savoir quels utilisateurs sont connectés, ne serait-ce que pour communiquer avec eux par l’envoi de messages.
| tty |
représente un terminal. |
| pts/ |
représente une console virtuelle sous environnement graphique. |
L’option « -r » affiche en plus le niveau d’exécution (voir chapitre « démarrage »).
Arborescence de fichiers
Sous Linux, l’arborescence des fichiers se présente sous la forme d’un arbre inversé, appelé arborescence hiérarchique unique, dont la racine est le répertoire « / ».
Le répertoire courant est le répertoire où se trouve l’utilisateur.
Le répertoire de connexion est le répertoire de travail
associé à l’utilisateur. Les répertoires de connexion sont, en
standard, stockés dans le répertoire /home.
À la connexion de l’utilisateur, le répertoire courant est le répertoire de connexion.
Un chemin absolu référence un fichier depuis la racine en parcourant l’arborescence complète jusqu’au niveau du fichier :
-
/home/groupeA/alice/monfichier
Le chemin relatif référence ce même fichier en parcourant l’arborescence complète depuis le répertoire courant :
-
../alice/monfichier
Dans l’exemple précèdent, les “..” font référence au répertoire parent du répertoire actuel.
Un répertoire, même s’il est vide, contiendra obligatoirement au minimum deux références :
« . »
|
référence sur lui-même. |
« .. »
|
référence le répertoire parent du répertoire actuel. |
Un chemin relatif peut ainsi commencer par « ./ » ou par « ../ ». Lorsque le chemin relatif fait référence à un sous dossier ou à un fichier du répertoire courant, alors le « ./ » est souvent omis. Mentionner le premier « ./ » de l’arborescence ne sera réellement requis que pour lancer un fichier exécutable.
Les erreurs dans les chemins peuvent être la cause de nombreux problèmes : création de dossier ou de fichiers aux mauvais endroits, suppressions involontaires, etc. Il est donc fortement recommandé d’utiliser l’auto-complétion (cf. 2.2) lors des saisies de chemin.
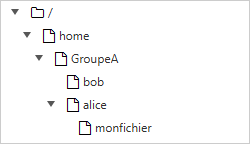
Dans l’exemple ci-dessus, nous cherchons à donner l’emplacement du fichier monfichier depuis le répertoire de bob.
-
Par un chemin absolu, le répertoire courant importe peu. Nous commençons par la racine, pour descendre successivement dans les répertoires “
home”, “groupeA”, “alice” et enfin le fichier “monfichier” :/home/groupeA/alice/monfichier. -
Par un chemin relatif, notre point de départ étant le répertoire courant “
bob”, nous remontons d’un niveau par “..” (soit dans le répertoiregroupeA), puis nous descendons dans le répertoire “alice”, et enfin le fichier “monfichier” :../alice/monfichier.
La commande pwd
La commande pwd (Print Working Directory) affiche le chemin absolu du répertoire courant.
$ pwd
/home/stagiairePour se déplacer à l’aide d’un chemin relatif, il faut impérativement connaître son positionnement dans l’arborescence.
Selon l’interpréteur de commandes, l’invite de commandes peut également afficher le nom du répertoire courant.
La commande cd
La commande cd (Change Directory) permet de changer le répertoire courant, autrement dit, de se déplacer dans l’arborescence.
$ cd /tmp
$ pwd
/tmp
$ cd ../
$ pwd
/
$ cd
$ pwd
/home/stagiaireComme vous pouvez le constater dans le dernier exemple ci-dessus, la commande cd sans argument permet de repositionner le répertoire courant sur le répertoire de connexion (home directory).
La commande ls
La commande ls affiche le contenu d’un répertoire.
ls [-a] [-i] [-l] [repertoire1] [repertoire2] […]Exemple :
$ ls /home
. .. stagiaireLes options principales de la commande ls sont :
| Option | Information |
|---|---|
|
Affiche tous les fichiers, même ceux cachés. Les fichiers cachés sous Linux sont ceux qui commencent par un “ |
|
Affiche les numéros d’inode. |
|
Affiche sous forme de liste verticale la liste des fichiers avec des informations supplémentaires formatées par colonnes. |
La commande ls offre toutefois de très nombreuses options (voir le man) :
| Option | Information |
|---|---|
|
Affiche les informations d’un répertoire au lieu de lister son contenu. |
|
Affiche les UID et GID plutôt que les noms des propriétaires. |
|
Affiche les tailles de fichiers dans le format le plus adapté (octet, kilo-octet, méga-octet, giga-octet, …). |
|
Affiche la taille en octets (sauf si option |
|
Affiche tous les fichiers du répertoire sauf “ |
|
Affiche récursivement le contenu des sous répertoires. |
|
Affiche le type des fichiers. Imprime un |
|
Trier les fichiers en fonction de leurs extensions. |
-
Description des colonnes :
$ ls -lia /home
78489 drwx------ 4 stagiaire users 4096 25 oct. 08:10 stagiaire| Valeur | Information. |
|---|---|
|
Numéro d’inode. |
|
Type de fichier ( |
|
Nombre de sous-répertoires (“ |
|
Utilisateur propriétaire. |
|
Groupe propriétaire. |
|
Taille en octets. |
|
Date de dernière modification. |
|
Nom du fichier (ou du répertoire). |
|
Des alias sont fréquemment positionnés au sein des distributions courantes. C’est le cas de l’alias Alias de la commande ls -l
|
La commande ls dispose de nombreuses options dont voici quelques exemples avancés d’utilisations :
-
Lister les fichiers de
/etcpar ordre de dernière modification :
$ ls -ltr /etc
total 1332
-rw-r--r--. 1 root root 662 29 aout 2007 logrotate.conf
-rw-r--r--. 1 root root 272 17 nov. 2009 mailcap
-rw-------. 1 root root 122 12 janv. 2010 securetty
...
-rw-r--r--. 2 root root 85 18 nov. 17:04 resolv.conf
-rw-r--r--. 1 root root 44 18 nov. 17:04 adjtime
-rw-r--r--. 1 root root 283 18 nov. 17:05 mtab-
Lister les fichiers de
/varplus gros qu’un méga-octet mais moins qu’un giga-octets :
[root]# ls -Rlh /var | grep [0-9]M
...
-rw-r--r--. 1 apache apache 1,2M 10 nov. 13:02 XB RiyazBdIt.ttf
-rw-r--r--. 1 apache apache 1,2M 10 nov. 13:02 XB RiyazBd.ttf
-rw-r--r--. 1 apache apache 1,1M 10 nov. 13:02 XB RiyazIt.ttf
...-
Afficher les droits sur un dossier :
Pour connaître les droits sur un dossier, dans notre exemple /etc, la commande suivante ne conviendrait pas :
$ ls -l /etc
total 1332
-rw-r--r--. 1 root root 44 18 nov. 17:04 adjtime
-rw-r--r--. 1 root root 1512 12 janv. 2010 aliases
-rw-r--r--. 1 root root 12288 17 nov. 17:41 aliases.db
drwxr-xr-x. 2 root root 4096 17 nov. 17:48 alternatives
...puisque cette dernière liste par défaut le contenu du dossier et non le contenant.
Pour ce faire, il faut utiliser l’option -d :
$ ls -ld /etc
drwxr-xr-x. 69 root root 4096 18 nov. 17:05 /etc-
Lister les fichiers par taille :
$ ls -lhS-
Afficher la date de modification au format “timestamp” :
$ ls -l --time-style="+%Y-%m-%d $newline%m-%d %H:%M" /
total 12378
dr-xr-xr-x. 2 root root 4096 2014-11-23 11-23 03:13 bin
dr-xr-xr-x. 5 root root 1024 2014-11-23 11-23 05:29 boot-
Ajouter le “trailing slash” à la fin des dossiers :
Par défaut, la commande ls n’affiche pas le dernier slash d’un dossier.
Dans certains cas, comme pour des scripts par exemple, il est utile de les afficher :
$ ls -dF /etc
/etc/-
Masquer certaines extensions :
$ ls /etc --hide=*.confLa commande mkdir
La commande mkdir crée un répertoire ou une arborescence de répertoire.
mkdir [-p] repertoire [repertoire] […]Exemple :
$ mkdir /home/stagiaire/travailLe répertoire « stagiaire » devra exister pour créer le répertoire « travail ».
Sinon, l’option « -p » devra être utilisée. L’option « -p » crée les répertoires parents s’ils n’existent pas.
|
Il est vivement déconseillé de donner des noms de commandes UNIX comme noms de répertoires ou fichiers. |
La commande touch
La commande touch modifie l’horodatage d’un fichier ou crée un fichier vide si le fichier n’existe pas.
touch [-t date] fichierExemple :
$ touch /home/stagiaire/fichier| Option | Information |
|---|---|
|
Modifie la date de dernière modification du fichier avec la date précisée. |
|
La commande touch est utilisée en priorité pour créer un fichier vide, mais elle peut avoir un intérêt dans le cadre de sauvegarde incrémentale ou différentielle. En effet, le fait d’exécuter un touch sur un fichier aura pour seul effet de forcer sa sauvegarde lors de la sauvegarde suivante. |
La commande rmdir
La commande rmdir supprime un répertoire vide.
Exemple :
$ rmdir /home/stagiaire/travail| Option | Information |
|---|---|
|
Supprime le ou les répertoire(s) parent(s) à la condition qu’ils soient vides. |
|
Pour supprimer à la fois un répertoire non-vide et son contenu, il faudra utiliser la commande |
La commande rm
La commande rm supprime un fichier ou un répertoire.
rm [-f] [-r] fichier [fichier] […]|
ATTENTION !!! Toute suppression de fichier ou de répertoire est définitive. |
| Options | Information |
|---|---|
|
Ne demande pas de confirmation de la suppression. |
|
Demande de confirmation de la suppression. |
|
Supprime récursivement les sous-répertoires. |
|
La commande La commande |
La suppression d’un dossier à l’aide de la commande rm, que ce dossier soit vide ou non, nécessitera l’ajout de l’option -r.
La fin des options est signalée au shell par un double tiret “--”.
Dans l’exemple :
$ >-dur-dur # Creer un fichier vide appelé -dur-dur
$ rm -f -- -dur-durLe nom du fichier -dur-dur commence par un “-”. Sans l’usage du “--” le shell aurait interprété le “-d” de “-dur-dur” comme une option.
La commande mv
La commande mv déplace et renomme un fichier.
mv fichier [fichier …] destinationExemples :
$ mv /home/stagiaire/fic1 /home/stagiaire/fic2
$ mv /home/stagiaire/fic1 /home/stagiaire/fic2 /tmp| Options | Information |
|---|---|
|
Ne demande pas de confirmation si écrasement du fichier de destination. |
|
Demande de confirmation si écrasement du fichier de destination (par défaut). |
Quelques cas concrets permettront de mieux saisir les difficultés qui peuvent se présenter :
$ mv /home/stagiaire/fic1 /home/stagiaire/fic2Permet de renommer “fic1” en “fic2”, si “fic2” existe déjà, il sera remplacé par “fic1”.
$ mv /home/stagiaire/fic1 /home/stagiaire/fic2 /tmpPermet de déplacer “fic1” et “fic2” dans le répertoire “/tmp”.
$ mv fic1 /repexiste/fic2« fic1 » est déplacé dans « /repexiste » et renommé « fic2 ».
$ mv fic1 fic2« fic1 » est renommé « fic2 ».
$ mv fic1 /repexisteSi le répertoire de destination existe, « fic1 » est déplacé dans « /repexiste ».
$ mv fic1 /repexistepasSi le répertoire de destination n’existe pas, « fic1 » est renommé « repexistepas » à la racine.
La commande cp
La commande cp copie un fichier.
cp fichier [fichier …] destinationExemple :
$ cp -r /home/stagiaire /tmp| Options | Information |
|---|---|
|
Demande de confirmation si écrasement (par défaut). |
|
Ne demande pas de confirmation si écrasement du fichier de destination. |
|
Conserve le propriétaire, les permissions et l’horodatage du fichier copié. |
|
Copie un répertoire avec ses fichiers et sous-répertoires. |
Quelques cas concrets permettront de mieux saisir les difficultés qui peuvent se présenter :
$ cp fic1 /repexiste/fic2« fic1 » est copié dans « /repexiste » sous le nom « fic2 ».
$ cp fic1 fic2« fic1 » est copié sous le nom « fic2 » dans ce répertoire.
$ cp fic1 /repexisteSi le répertoire de destination existe, « fic1 » est copié dans « /repexiste ».
$ cp fic1 /repexistepasSi le répertoire de destination n’existe pas, « fic1 » est copié sous le nom « repexistepas ».
Visualisation
La commande file
La commande file affiche le type d’un fichier.
file fichier [fichiers]Exemple :
$ file /etc/passwd /etc
/etc/passwd: ASCII text
/etc: directoryLa commande more
La commande more affiche le contenu d’un ou de plusieurs fichiers écran par écran.
more fichier [fichiers]Exemple :
$ more /etc/passwd
root:x:0:0:root:/root:/bin/bash
...En utilisant la touche ENTREE, le déplacement se fait ligne par ligne. En utilisant la touche ESPACE, le déplacement se fait page par page.
La commande less
La commande less affiche le contenu d’un ou de plusieurs fichiers. La commande less est interactive et possède des commandes d’utilisation qui lui sont propres.
less fichiers [fichiers]Les commandes propres à less sont :
| Commande | Action |
|---|---|
|
Aide. |
|
Monter, descendre d’une ligne ou pour aller à droite ou à gauche. |
|
Descendre d’une ligne. |
|
Descendre d’une page. |
|
Monter ou descendre d’une page. |
|
Se placer en début de fichier ou en fin de fichier. |
|
Rechercher le texte. |
|
Quitter la commande less. |
La commande cat
La commande cat concatène (mettre bout à bout) le contenu de plusieurs fichiers et affiche le résultat sur la sortie standard.
cat fichier [fichiers]Exemple 1 - Afficher le contenu d’un fichier vers la sortie standard :
$ cat /etc/passwdExemple 2 - Afficher le contenu de plusieurs fichiers vers la sortie standard :
$ cat /etc/passwd /etc/groupExemple 3 - Afficher le contenu de plusieurs fichiers et rediriger la sortie standard :
$ cat /etc/passwd /etc/group > utilisateursEtGroupes.txtExemple 4 - Afficher la numérotation des lignes :
$ cat -n /etc/passwd
1 root:x:0:0:root:/root:/bin/bash
2 bin:x:1:1:bin:/bin:/sbin/nologin
...Exemple 5 - Affiche la numérotation des lignes non vides :
$ cat -b /etc/openldap/ldap.conf
1 #
2 # LDAP Defaults
3 #
4 # See ldap.conf(5) for details
5 # This file should be world readable but not world writableLa commande tac
La commande tac fait quasiment l’inverse de la commande cat. Elle affiche le contenu d’un fichier en commençant par la fin (ce qui est particulièrement intéressant pour la lecture des logs !).
Exemple : Afficher un fichier de logs en affichant en premier la dernière ligne :
[root]# tac /var/log/messages | lessLa commande head
La commande head affiche le début d’un fichier.
head [-n x] fichier| Option | Observation |
|---|---|
|
Affiche les x premières lignes du fichier |
Par défaut (sans l’option -n), la commande head affichera les 10 premières lignes du fichier.
La commande tail
La commande tail affiche la fin d’un fichier.
tail [-f] [-n x] fichier| Option | Observation |
|---|---|
|
Affiche les |
|
Affiche les modifications du fichier en temps réel |
Exemple :
$ tail -n 3 /etc/passwd
sshd:x:74:74:Privilege-separeted sshd:/var/empty /sshd:/sbin/nologin
tcpdump::x:72:72::/:/sbin/nologin
user1:x:500:500:grp1:/home/user1:/bin/bashAvec l’option -f, la commande tail ne rend pas la main et s’exécute tant que l’utilisateur ne l’interrompt pas par la séquence [CTRL] + [C]. Cette option est très fréquemment utilisée pour suivre les fichiers journaux (les logs) en temps réel.
Sans l’option -n, la commande tail affiche les 10 dernières lignes du fichier.
La commande sort
La commande sort trie les lignes d’un fichier.
Elle permet d’ordonner, ranger dans un ordre donné, le résultat d’une commande ou le contenu d’un fichier, selon un ordre numérique, alphabétique, par ordre de grandeur (Ko, Mo, Go) ou dans l’ordre inverse.
sort [-kx] [-n] [-o fichier] [-ty] fichierExemple :
$ sort -k3 -t: -n /etc/passwd
root:x:0:0:root:/root:/bin/bash
adm:x:3:4:adm:/var/adm/:/sbin/nologin| Option | Observation |
|---|---|
|
Précise la colonne |
|
Demande un tri numérique |
|
Enregistre le tri dans le fichier précisé |
|
Précise le caractère séparateur de champs |
|
Inverse l’ordre du résultat |
La commande sort ne trie le fichier qu’à l’affichage écran. Le fichier n’est pas modifié par le tri. Pour enregistrer le tri, il faut utiliser l’option -o ou une redirection de sortie >.
Par défaut, le tri des nombres se fait selon leur caractère. Ainsi, “110” sera avant “20”, qui sera lui-même avant “3”. Il faut préciser l’option -n pour que les blocs caractères numériques soient bien triés par leur valeur.
La commande sort permet d’inverser l’ordre des résultats, avec l’option -r :
$ sort -k3 -t: -n -r /etc/passwd
root:x:0:0:root:/root:/bin/bash
adm:x:3:4:adm:/var/adm/:/sbin/nologinDans cet exemple, la commande sort rangera cette fois-ci le contenu du fichier /etc/passwd du plus grand uid au plus petit.
Quelques exemples avancés d’utilisation de la commande sort :
-
Mélanger les valeurs
La commande sort permet également de mélanger les valeurs avec l’option -R :
$ sort -R /etc/passwd-
Trier des adresses IP
Un administrateur système est rapidement confronté au traitement des adresses IP issues des logs de ses services comme SMTP, VSFTP ou Apache. Ces adresses sont typiquement extraites avec la commande cut.
Voici un exemple avec le fichier client-dns.txt :
192.168.1.10
192.168.1.200
5.1.150.146
208.128.150.98
208.128.150.99$ sort -nr client-dns.txt
208.128.150.99
208.128.150.98
192.168.1.200
192.168.1.10
5.1.150.146-
Trier des tailles de fichiers
La commande sort sait reconnaître les tailles de fichiers, issues de commande comme ls avec l’option -h.
Voici un exemple avec le fichier taille.txt :
1,7G
18M
69K
2,4M
1,2M
4,2G
6M
124M
12,4M
4G[root]# sort -hr taille.txt
4,2G
4G
1,7G
124M
18M
12,4M
6M
2,4M
1,2M
69KLa commande wc
La commande wc compte le nombre de lignes, mots ou octets d’un fichier.
wc [-l] [-m] [-w] fichier [fichiers]| Option | Observation |
|---|---|
|
Compte le nombre d’octets. |
|
Compte le nombre de caractères. |
|
Compte le nombre de lignes. |
|
Compte le nombre de mots. |
Recherche
La commande find
La commande find recherche l’emplacement d’un fichier.
find repertoire [-name nom] [-type type] [-user login] [-date date]Les options de la commande find étant très nombreuses, il est préférable de se référer au man.
Si le répertoire de recherche n’est pas précisé, la commande find cherchera à partir du répertoire courant.
| Option | Observation |
|---|---|
|
Recherche des fichiers selon leurs permissions. |
|
Recherche des fichiers selon leur taille. |
L’option -exec de la commande find
Il est possible d’utiliser l’option -exec de la commande find pour exécuter une commande à chaque ligne de résultat :
$ find /tmp -name *.txt -exec rm -f {} \;La commande précédente recherche tous les fichiers du répertoire /tmp nommés *.log et les supprime.
|
Comprendre l’option -exec Dans l’exemple ci-dessus, la commande find va construire une chaîne de caractères représentant la commande à exécuter. Si la commande find trouve trois fichiers nommés Ce qui nous donnera : Le caractère “ |
La commande whereis
La commande whereis recherche des fichiers liés à une commande.
whereis [-b] [-m] [-s] commandeExemple :
$ whereis -b ls
ls: /bin/ls| Option | Observation |
|---|---|
|
Ne recherche que le fichier binaire. |
|
Ne recherche que les pages de manuel. |
|
Ne recherche que les fichiers sources. |
La commande grep
La commande grep recherche une chaîne de caractères dans un fichier.
grep [-w] [-i] [-v] "chaîne" fichierExemple :
$ grep -w "root:" /etc/passwd
root:x:0:0:root:/root:/bin/bash| Option | Observation |
|---|---|
|
Ignore la casse de la chaîne de caractères recherchée. |
|
Inverse le résultat de la recherche. |
|
Recherche exactement la chaîne de caractères précisée. |
La commande grep retourne la ligne complète comprenant la chaîne de caractères recherchée.
-
Le caractère spécial
^permet de rechercher une chaîne de caractères placée en début de ligne. -
Le caractère spécial
$permet de rechercher une chaîne de caractères placée en fin de ligne.
$ grep -w "^root" /etc/passwd|
Cette commande est très puissante et il est fortement conseillé de consulter son manuel. Elle a de nombreux dérivés, |
Il est possible de rechercher une chaîne de caractères dans une arborescence de fichiers avec l’option -R.
$ grep -R "Virtual" /etc/httpdLes méta-caractères
Les méta-caractères se substituent à un ou plusieurs caractères (voire à une absence de caractère) lors d’une recherche.
Ils sont combinables.
Le caractère * remplace une chaîne composée de plusieurs caractères quelconques. Le caractère * peut également représenter une absence de caractère.
$ find /home -name test*
/home/stagiaire/test
/home/stagiaire/test1
/home/stagiaire/test11
/home/stagiaire/tests
/home/stagiaire/test362Les méta-caractères permettent des recherches plus complexes en remplaçant tout ou partie d’un mot. Il suffit de remplacer les inconnues par ces caractères spéciaux.
Le caractère “?” remplace un unique caractère, quel qu’il soit.
$ find /home -name test?
/home/stagiaire/test1
/home/stagiaire/testsLes crochets “[ ]” permettent de spécifier les valeurs que peut prendre un unique caractère.
$ find /home -name test[123]*
/home/stagiaire/test1
/home/stagiaire/test11
/home/stagiaire/test362|
Il ne faut pas confondre les méta-caractères du shell et ceux des expressions régulières. La commande grep utilise les méta-caractères des expressions régulières. |
Redirections et tubes
L’entrée et les sorties standards
Sur les systèmes UNIX et Linux, les flux standards sont aux nombres de trois. Ils permettent aux programmes, via la bibliothèque stdio.h de faire entrer ou sortir des informations.
Ces flux sont appelés canal X ou descripteur X de fichier.
Par défaut :
-
le clavier est le périphérique d’entrée pour le canal 0, appelé stdin ;
-
l’écran est le périphérique de sortie pour les canaux 1 et 2, appelés stdout et stderr.
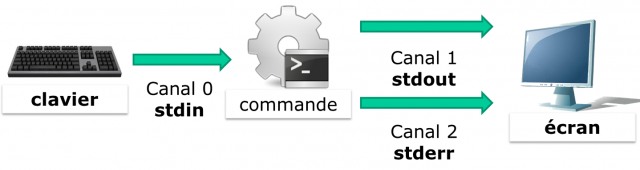
stderr reçoit les flux d’erreurs renvoyés par une commande. Les autres flux sont dirigés vers stdout.
Ces flux pointent vers des fichiers périphériques, mais comme tout est fichier sous UNIX, les flux d’entrées/sorties peuvent facilement être détournés vers d’autres fichiers. Ce principe fait toute la force du shell.
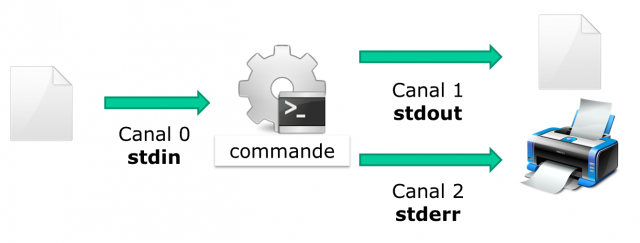
La redirection d’entrée
Il est possible de rediriger le flux d’entrée depuis un autre fichier avec le caractère inférieur < ou <<. La commande lira le fichier au lieu du clavier :
$ ftp -in serverftp << cdes-ftp.txt|
Seules les commandes demandant une saisie au clavier pourront gérer la redirection d’entrée. |
La redirection d’entrée peut également être utilisée pour simuler une interactivité avec l’utilisateur. La commande lira le flux d’entrée jusqu’à rencontrer le mot clef défini après la redirection d’entrée.
Cette fonctionnalité est utilisée pour scripter des commandes interactives :
$ ftp -in serverftp << FIN
user alice password
put fichier
bye
FINLe mot clef FIN peut être remplacé par n’importe quel mot.
$ ftp -in serverftp << STOP
user alice password
put fichier
bye
STOPLe shell quitte la commande ftp lorsqu’il reçoit une ligne ne contenant que le mot clef.
La redirection de l’entrée standard est peu utilisée car la plupart des commandes acceptent un nom de fichier en argument.
La commande wc pourrait s’utiliser ainsi :
$ wc -l .bash_profile
27 .bash_profile # le nombre de lignes est suivi du nom du fichier
$ wc -l < .bash_profile
27 # le nombre de lignes est seulLes redirections de sortie
Les sorties standards peuvent être redirigées vers d’autres fichiers grâce aux caractères > ou >>.
La redirection simple > écrase le contenu du fichier de sortie :
$ date +%F > fic_datealors que la redirection double >> ajoute (concatène) au contenu du fichier de sortie.
$ date +%F >> fic_dateDans les deux cas, le fichier est automatiquement créé lorsqu’il n’existe pas.
La sortie d’erreur standard peut être également redirigée vers un autre fichier. Cette fois-ci, il faudra préciser le numéro du canal (qui peut être omis pour les canaux 0 et 1) :
$ ls -R / 2> fic_erreurs
$ ls -R / 2>> fic_erreursExemples de redirections
Redirection de 2 sorties vers 2 fichiers :
$ ls -R / >> fic_ok 2>> fic_nokRedirection des 2 sorties vers un fichier unique :
$ ls -R / >> fic_log 2>&1Redirection de stderr vers un "puits sans fond" (/dev/null) :
$ ls -R / 2>> /dev/nullLorsque les 2 flux de sortie sont redirigés, aucune information n’est affichée à l’écran. Pour utiliser à la fois la redirection de sortie et conserver l’affichage, il faudra utiliser la commande tee.
Les tubes (pipe)
Un tube (pipe en anglais) est un mécanisme permettant de relier la sortie standard d’une première commande vers l’entrée standard d’une seconde.
Cette communication est monodirectionnelle et se fait grâce au symbole |. Le symbole pipe “|” est obtenu en appuyant simultanément sur les touches AltGR+6.

Toutes les données envoyées par la commande à gauche du tube à travers le canal de sortie standard sont envoyées au canal d’entrée standard de la commande placée à droite.
Les commandes particulièrement utilisées après un pipe sont des filtres.
-
Exemples :
# N'afficher que le début :
$ ls -lia / | head
# N'afficher que la fin :
$ ls -lia / | tail
# Trier le résultat
$ ls -lia / | sort
# Compter le nombre de mots / caractères
$ ls -lia / | wc
# Chercher une chaîne de caractères dans le résultat :
$ ls -lia / | grep fichierPoints particuliers
La commande tee
La commande tee permet de rediriger la sortie standard d’une commande vers un fichier tout en maintenant l’affichage à l’écran.
Elle est combinée avec le pipe “|” pour recevoir en entrée la sortie de la commande à rediriger.
$ ls -lia / | tee fic
$ cat ficL’option -a permet d’ajouter au fichier au lieu de l’écraser.
Les commandes alias et unalias
Utiliser les alias est un moyen pour demander au shell de se souvenir d’une commande particulière avec ses options et lui donner un nom.
Par exemple :
$ llremplacera la commande :
$ ls -lLa commande alias liste les alias de la session en cours. Des alias sont positionnés par défaut sur les distributions Linux. Ici, les alias d’un serveur CentOS :
$ alias
alias l.='ls -d .* --color=auto'
alias ll='ls -l --color=auto'
alias ls='ls --color=auto'
alias vi='vim'
alias which='alias | /usr/bin/which --tty-only --read-alias --show-dot --show-tilde'Les alias ne sont définis que de façon temporaire, le temps de la session utilisateur.
Pour une utilisation permanente, il faut les créer dans le fichier :
-
.bashrcdu répertoire de connexion de l’utilisateur ; -
/etc/profile.d/alias.shpour tous les utilisateurs.
|
Une attention particulière doit être portée lors de l’usage d’alias qui peuvent potentiellement s’avérer dangereux ! Par exemple, un alias mis en place à l’insu de l’administrateur : |
La commande unalias permet de supprimer les alias.
$ unalias ll
# Pour supprimer tous les alias :
$ unalias -aAlias et fonctions utiles
-
Alias
grep
Colorise le résultat de la commande grep :
alias grep='grep --color=auto'-
Fonction
mcd
Il est fréquent de créer un dossier puis de se déplacer dedans :
mcd() { mkdir -p "$1"; cd "$1"; }-
Fonction
cls
Se déplacer dans un dossier et lister son contenu :
cls() { cd "$1"; ls; }-
Fonction
backup
Créer une copie de sauvegarde d’un fichier :
backup() { cp "$1"{,.bak}; }-
Fonction
extract
Extrait tout type d’archive :
extract () {
if [ -f $1 ] ; then
case $1 in
*.tar.bz2) tar xjf $1 ;;
*.tar.gz) tar xzf $1 ;;
*.bz2) bunzip2 $1 ;;
*.rar) unrar e $1 ;;
*.gz) gunzip $1 ;;
*.tar) tar xf $1 ;;
*.tbz2) tar xjf $1 ;;
*.tgz) tar xzf $1 ;;
*.zip) unzip $1 ;;
*.Z) uncompress $1 ;;
*.7z) 7z x $1 ;;
*)
echo "'$1' cannot be extracted via extract()" ;;
esac
else
echo "'$1' is not a valid file"
fi
}-
Alias
cmount
alias cmount="mount | column -t"
[root]# cmount
/dev/simfs on / type simfs (rw,relatime,usrquota,grpquota)
proc on /proc type proc (rw,relatime)
sysfs on /sys type sysfs (rw,relatime)
none on /dev type devtmpfs (rw,relatime,mode=755)
none on /dev/pts type devpts (rw,relatime,mode=600,ptmxmode=000)
none on /dev/shm type tmpfs (rw,relatime)
none on /proc/sys/fs/binfmt_misc type binfmt_misc (rw,relatime)Le caractère ;
Le caractère ; chaîne les commandes.
Les commandes s’exécuteront toutes séquentiellement dans l’ordre de saisie une fois que l’utilisateur aura appuyé sur [ENTREE].
$ ls /; cd /home; ls -lia; cd /Editeur de texte VI
Introduction
Visual (VI) est un éditeur de texte très populaire sous Linux malgré une ergonomie qui semble limitée. C’est en effet un éditeur entièrement en mode texte : chacune des actions se faisant avec une touche du clavier ou des commandes dédiées.
Très puissant, il est surtout très pratique puisqu’il est présent dans le noyau et donc accesssible en cas de défaillance du système. Son universalité (il est présent sur toutes les distributions Linux et sous Unix) en fait un outil incontournable de l’administrateur.
Ses fonctionnalités sont :
-
Insertion, suppression, modification de texte ;
-
Copie de mots, lignes ou blocs de texte ;
-
Recherche et remplacement de caractères.
La commande vi
La commande vi ouvre l’éditeur de texte VI.
vi [-c commande] [fichier]Exemple :
$ vi /home/stagiaire/fichier| Option | Information |
|---|---|
|
Exécute VI en précisant une commande à l’ouverture |
Si le fichier existe à l’endroit mentionné par le chemin, celui-ci est lu par VI qui se place en mode Commandes.
Si le fichier n’existe pas, VI ouvre un fichier vierge et une page vide est affichée à l’écran. A l’enregistrement du fichier, celui-ci prendra le nom précisé avec la commande.
Si la commande vi est exécutée sans préciser de nom de fichier, VI ouvre un fichier vierge et une page vide est affichée à l’écran. A l’enregistrement du fichier, VI demandera un nom de fichier.
L’éditeur vim reprend l’interface et les fonctions de VI avec de nombreuses améliorations.
vim [-c commande] [fichier]Parmi ces améliorations, l’utilisateur dispose de la coloration syntaxique, très utile pour éditer des scripts shell.
Pendant une session, VI utilise un fichier tampon dans lequel il inscrit toutes les modifications effectuées par l’utilisateur.
|
Tant que l’utilisateur n’a pas enregistré son travail, le fichier d’origine n’est pas modifié. |
Au démarrage, VI est en mode commandes.
|
Une ligne de texte se termine en appuyant sur ENTREE mais si l’écran n’est pas assez large, VI effectue des retours à la ligne automatiques. |
Pour sortir de VI, il faut, depuis le mode Commandes, taper sur : puis saisir :
-
qpour sortir sans sauvegarder ; -
wpour enregistrer son travail ; -
wqouxpour sortir et sauvegarder.
Pour forcer la sortie sans confirmation, il faut ajouter ! aux commandes précédentes.
|
Il n’y a pas de sauvegarde automatique, il faut donc penser à sauvegarder son travail régulièrement. |
Mode opératoires
Dans VI, il existe 3 modes de travail :
-
Le mode Commandes ;
-
Le mode Insertion ;
-
Le mode Ex.
La philosophie de VI est d’alterner entre le mode Commandes et le mode Insertion.
Le troisième mode, Ex, est un mode de commandes de bas de page issu d’un ancien éditeur de texte.
Le mode Commandes
C’est le mode par défaut au démarrage de VI. Pour y accéder à partir d’un des autres modes, il suffit de taper sur la touche ECHAP.
Toutes les saisies sont interprétées comme des commandes et les actions correspondantes sont exécutées. Ce sont essentiellement des commandes permettant la modification de texte (copier, coller, …).
Les commandes ne s’affichent pas à l’écran.
Le mode Insertion
C’est le mode de modification du texte. Pour y accéder à partir du mode Commandes, il faut taper sur des touches particulières qui effectueront une action en plus de changer de mode.
La saisie du texte ne s’effectue pas directement sur le fichier mais dans une zone tampon de la mémoire. Les modifications ne sont effectives que lors de l’enregistrement du fichier.
Le mode Ex
C’est le mode de modification du fichier. Pour y accéder, il faut d’abord passer en mode Commandes, puis saisir la commande Ex commençant fréquemment par le caractère :.
La commande est validée en appuyant sur la touche ENTREE.
Déplacer le curseur
En mode Commandes, il existe plusieurs façons de déplacer le curseur.
La souris n’étant pas active, il est possible de le déplacer caractère par caractère, mais des raccourcis existent pour aller plus vite.
VI reste en mode Commandes après le déplacement du curseur.
Le curseur est placé sous le caractère désiré.
À partir d’un caractère
-
Déplacement d’un ou
ncaractères vers la gauche :
[←] ou [n][←]
-
Déplacement d’un ou
ncaractères vers la droite :
[→] ou [n][→]
-
Déplacement d’un ou
ncaractères vers le haut :
[↑] ou [n][↑]
-
Déplacement d’un ou
ncaractères vers le bas :
[↓] ou [n][↓]
-
Déplacement à la fin de la ligne :
[$] ou [FIN]
-
Déplacement au début de la ligne :
[0] ou [POS1]
À partir du premier caractère d’un mot
Les mots sont constitués de lettres ou de chiffres. Les caractères de ponctuation et les apostrophes séparent les mots.
Si le curseur se trouve au milieu d’un mot [w] passe au mot suivant, [b] passe au début du mot.
Si la ligne est finie, VI passe automatiquement à la ligne suivante.
-
Déplacement d’un ou
nmots vers la droite :
[w] ou [n][w]
-
Déplacement d’un ou
nmots vers la gauche :
[b] ou [n][b]
À partir du premier caractère d’une ligne
-
Déplacement à la dernière ligne du texte :
[G]
-
Déplacement à la ligne
n:
[n][G]
-
Déplacement à la première ligne de l’écran :
[H]
-
Déplacement à la ligne du milieu de l’écran :
[M]
-
Déplacement à la dernière ligne de l’écran :
[L]
Insérer du texte
En mode Commandes, il existe plusieurs façons d’insérer du texte.
VI bascule en mode Insertion après la saisie d’une de ces touches.
|
VI bascule en mode Insertion. Il faudra donc appuyer sur la touche ECHAP pour revenir en mode Commandes. |
Par rapport à un caractère
-
Insertion de texte avant un caractère :
[i]
-
Insertion de texte après un caractère :
[a]
Par rapport à une ligne
-
Insertion de texte au début d’une ligne :
[I]
-
Insertion de texte à la fin d’une ligne :
[A]
Par rapport au texte
-
Insertion de texte avant une ligne :
[O]
-
Insertion de texte après une ligne :
[o]
Caractères, mots et lignes
VI permet l’édition de texte en gérant :
-
les caractères,
-
les mots,
-
les lignes.
Il est possible pour chaque cas de :
-
supprimer,
-
remplacer,
-
copier,
-
couper,
-
coller.
Ces opérations se font en mode Commandes.
Caractères
-
Supprimer un ou
ncaractères :
[x] ou [n][x]
-
Remplacer un caractère par un autre :
[r][caractère]
-
Remplacer plus d’un caractère par d’autres :
[R][caractères][ECHAP]
|
La commande [R] bascule en mode Remplacement, qui est une sorte de mode Insertion. |
Mots
-
Supprimer (couper) un ou
nmots :
[d][w] ou [n][d][w]
-
Copier un ou
nmots :
[y][w] ou [n][y][w]
-
Coller un mot une ou
nfois après le curseur :
[p] ou [n][p]
-
Coller un mot une ou
nfois avant le curseur :
[P] ou [n][P]
-
Remplacer un mot :
[c][w][mot][ECHAP]
|
Il faut positionner le curseur sous le premier caractère du mot à couper (ou copier) sinon VI coupera (ou copiera) seulement la partie du mot entre le curseur et la fin. Supprimer un mot revient à la couper. S’il n’est pas collé ensuite, le tampon est vidé et le mot est supprimé. |
Lignes
-
Supprimer (couper) une ou
nlignes :
[d][d] ou [n][d][d]
-
Copier une ou
nlignes :
[y][y] ou [n][y][y]
-
Coller ce qui a été copié ou supprimé une ou
nfois après la ligne courante :
[p] ou [n][p]
-
Coller ce qui a été copié ou supprimé une ou
nfois avant la ligne courante :
[P] ou [n][P]
-
Supprimer (couper) du début de la ligne jusqu’au curseur :
[d][0]
-
Supprimer (couper) du curseur jusqu’à la fin de la ligne :
[d][$]
-
Copier du début de la ligne jusqu’au curseur :
[y][0]
-
Copier du curseur jusqu’à la fin de la ligne :
[y][$]
-
Supprimer (couper) le texte à partir de la ligne courante :
[d][L] ou [d][G]
-
Copier le texte à partir de la ligne courante :
[y][L] ou [y][G]
Annuler une action
-
Annuler la dernière action :
[u]
-
Annuler les actions sur la ligne courante :
[U]
Commandes EX
Le mode Ex permet d’agir sur le fichier (enregistrement, mise en page, options, …). C’est aussi en mode Ex que se saisissent les commandes de recherche et de remplacement. Les commandes sont affichées en bas de page et doivent être validées avec la touche ENTREE.
Pour passer en mode Ex, du mode Commandes, taper [:].
Numéroter les lignes
-
Afficher/masquer la numérotation :
:set nu
:set nonu
Rechercher une chaîne de caractères
-
Rechercher une chaîne de caractères à partir du curseur :
/chaîne
-
Rechercher une chaîne de caractères avant le curseur :
?chaîne
-
Aller à l’occurrence trouvée suivante :
[n]
-
Aller à l’occurence trouvée précédente :
[N]
Il existe des caractères jokers permettant de faciliter la recherche sous VI.
-
[]: Recherche d’un unique caractère dont les valeurs possibles sont précisées.
Exemple :
/[Mm]ot.
-
^: Recherche d’une chaîne débutant la ligne.
Exemple :
/Mot.
-
,$: Recherche d’une chaîne finissant la ligne.
Exemple :
/Mot,$
-
*: Recherche d’un ou de plusieurs caractères, quels qu’ils soient.
Exemple :
/M*t
Remplacer une chaîne de caractères
De la 1ère à la dernière ligne du texte, remplacer la chaîne recherchée par la chaîne précisée :
:1,$s/recherche/remplace
De la ligne n à la ligne m, remplacer la chaîne recherchée par la chaîne précisée :
:n,ms/recherche/remplace
Par défaut, seule la première occurence trouvée de chaque ligne est remplacée. Pour forcer le remplacement de chaque occurence, il faut ajouter /g à la fin de la commande :
:n,ms/recherche/remplace/g
Opérations sur les fichiers
-
Enregistrer le fichier :
:w
-
Enregistrer sous un autre nom :
:w fichier
-
Enregistrer de la ligne
nà la lignemdans un autre fichier :
:n,mw fichier
-
Recharger le dernier enregistrement du fichier :
e!
-
Coller le contenu d’un autre fichier après le curseur :
:r fichier
-
Quitter le fichier sans enregistrer :
:q
-
Quitter le fichier et enregistrer :
:wq ou :x
Autres fonctions
Il est possible d’exécuter VI en précisant les options à charger pour la session. Pour cela, il faut utiliser l’option -c :
$ vi -c "set nu" /home/stagiaire/fichierIl est aussi possible de saisir les commandes Ex dans un fichier nommé .exrc mis dans le répertoire de connexion de l’utilisateur. À chaque démarrage de VI ou de VIM les commandes seront lues et appliquées.
La commande vimtutor
Il existe un tutoriel pour apprendre à utiliser VI. Il est accessible avec la commande vimtutor.
$ vimtutorLa gestion des utilisateurs
Généralités
Chaque utilisateur est membre d’au moins un groupe : c’est son groupe principal.
Plusieurs utilisateurs peuvent faire partie d’un même groupe.
Les utilisateurs peuvent appartenir à d’autres groupes. Ces utilisateurs sont invités dans ces groupes secondaires.
|
Chaque utilisateur possède un groupe principal et peut être invité dans un ou plusieurs groupes secondaires. Les groupes et utilisateurs se gèrent par leur identifiant numérique unique Les fichiers de configuration se trouvent dans |
UID
|
User IDentifier. Identifiant unique d’utilisateur. |
GID
|
Group IDentifier. Identifiant unique de groupe. |
|
Il est recommandé d’utiliser les commandes d’administration au lieu de modifier manuellement les fichiers. |
Gestion des groupes
Fichiers modifiés, ajout de lignes :
-
/etc/group -
/etc/gshadow
Commande groupadd
La commande groupadd permet d’ajouter un groupe au système.
groupadd [-f] [-g GID] groupeExemple :
[root]# groupadd -g 512 GroupeB| Option | Description |
|---|---|
|
|
|
Le système choisit un |
|
Crée un groupe système avec un |
Règles de nommage des groupes :
-
Pas d’accents, ni caractères spéciaux ;
-
Différents du nom d’un utilisateur ou fichier système existant.
|
Sous Debian, l’administrateur devrait privilégier, sauf dans des scripts ayant la vocation d’être portables vers toutes les distributions Linux, les commandes addgroup/delgroup comme précisé dans le man : |
Commande groupmod
La commande groupmod permet de modifier un groupe existant sur le système.
groupmod [-g GID] [-n nom] groupeExemple :
[root]# groupmod -g 516 GroupeP
[root]# groupmod -n GroupeC GroupeB| Option | Description |
|---|---|
|
Nouveau |
|
Nouveau nom. |
Il est possible de modifier le nom d’un groupe, son GID ou les deux simultanément.
Après modification, les fichiers appartenant au groupe ont un GID inconnu. Il faut leur réattribuer le nouveau GID.
[root]# find / -gid 502 -exec chgrp 516 {} \;Commande groupdel
La commande groupdel permet de supprimer un groupe existant sur le système.
groupdel groupeExemple :
[root]# groupdel GroupeC|
Pour être supprimé, un groupe ne doit plus contenir d’utilisateurs. |
La suppression du dernier utilisateur d’un groupe éponyme entraînera la suppression de ce groupe par le système.
|
Chaque groupe possède un |
|
Un utilisateur faisant obligatoirement partie d’un groupe, il est nécessaire de créer les groupes avant d’ajouter les utilisateurs. Par conséquent, un groupe peut ne pas avoir de membres. |
Fichier /etc/group
Ce fichier contient les informations de groupes (séparées par :).
[root]# tail -1 /etc/group
GroupeP:x:516:stagiaire
(1) (2)(3) (4)| 1 |
Nom du groupe. |
| 2 |
Mot de passe ( |
| 3 |
GID. |
| 4 |
Membres invités (séparés par des virgules, ne contient pas les membres principaux). |
|
Chaque ligne du fichier Cette information d’appartenance est en fait déjà fournie par le fichier |
Fichier /etc/gshadow
Ce fichier contient les informations de sécurité sur les groupes (séparées par :).
[root]# grep GroupeA /etc/gshadow
GroupeA:$6$2,9,v...SBn160:alain:stagiaire
(1) (2) (3) (4)| 1 |
Nom du groupe. |
| 2 |
Mot de passe chiffré. |
| 3 |
Administrateur du groupe. |
| 4 |
Membres invités (séparés par des virgules, ne contient pas les membres principaux). |
|
Pour chaque ligne du fichier |
Un ! au niveau du mot de passe indique que celui-ci est bloqué.
Ainsi aucun utilisateur ne peut utiliser le mot de passe pour accéder au groupe (sachant que les membres du groupe n’en ont pas besoin).
Gestion des utilisateurs
Définition
Un utilisateur se définit comme suit dans le fichier /etc/passwd :
| 1 |
Login ; |
| 2 |
Mot de passe ; |
| 3 |
UID ; |
| 4 |
GID du groupe principal ; |
| 5 |
Commentaire ; |
| 6 |
Répertoire de connexion ; |
| 7 |
Interpréteur de commandes ( |
Il existe trois types d’utilisateurs :
-
root : Administrateur du système ;
-
utilisateur système : Utilisé par le système pour la gestion des droits d’accès des applications ;
-
utilisateur ordinaire : Autre compte permettant de se connecter au système.
Fichiers modifiés, ajout de lignes :
-
/etc/passwd -
/etc/shadow
Commande useradd
La commande useradd permet d’ajouter un utilisateur.
useradd [-u UID] [-g GID] [-d répertoire] [-s shell] loginExemple :
[root]# useradd -u 1000 -g 513 -d /home/GroupeC/carine carine| Option | Description |
|---|---|
|
|
|
|
|
Répertoire de connexion. |
|
Interpréteur de commandes. |
|
Ajoute un commentaire. |
|
Ajoute l’utilisateur à un groupe portant le même nom créé simultanément. |
|
Ne crée pas le répertoire de connexion. |
À la création, le compte ne possède pas de mot de passe et est verrouillé. Il faut assigner un mot de passe pour déverrouiller le compte.
Règles de nommage des comptes :
-
Pas d’accents, de majuscules ni caractères spéciaux ;
-
Différents du nom d’un groupe ou fichier système existant ;
-
Définir les options
-u,-g,-det-sà la création.
|
L’arborescence du répertoire de connexion doit être créée à l’exception du dernier répertoire.
Le dernier répertoire est créé par la commande |
Un utilisateur peut faire partie de plusieurs groupes en plus de son groupe principal.
Pour les groupes secondaires, il faut utiliser l’option -G.
Exemple :
[root]# useradd -u 500 -g GroupeA -G GroupeP,GroupeC albert|
Sous Debian, il faudra spécifier l’option |
Valeur par défaut de création d’utilisateur.
Modification du fichier /etc/default/useradd.
useradd -D [-b répertoire] [-g groupe] [-s shell]Exemple :
[root]# useradd -D -g 500 -b /home -s /bin/bash| Option | Description |
|---|---|
|
Définit les valeurs par défaut de création d’utilisateur. |
|
Définit le répertoire de connexion par défaut. |
|
Définit le groupe par défaut. |
|
Définit le shell par défaut. |
|
Nombre de jours suivant l’expiration du mot de passe avant que le compte ne soit désactivé. |
|
Date à laquelle le compte sera désactivé. |
Commande usermod
La commande usermod permet de modifier un utilisateur.
usermod [-u UID] [-g GID] [-d répertoire] [-m] loginExemple :
[root]# usermod -u 544 carineOptions identiques à la commande useradd.
| Option | Description |
|---|---|
|
Associé à l’option |
|
Nouveau nom. |
|
Date d’expiration du compte. |
|
Verrouille le compte. |
|
Déverrouille le compte. |
|
Empêche la suppression de l’utilisateur d’un groupe secondaire lors de l’ajout dans un autre groupe secondaire. |
|
Précise plusieurs groupes secondaires lors de l’ajout. |
Avec la commande usermod, le verrouillage d’un compte se traduit par l’ajout de ! devant le mot de passe dans le fichier /etc/shadow.
|
Pour être modifié un utilisateur doit être déconnecté et ne pas avoir de processus en cours. |
Après modification de l’identifiant, les fichiers appartenant à l’utilisateur ont un UID inconnu. Il faut leur réattribuer le nouvel UID.
[root]# find / -uid 1000 -exec chown 544: {} \;Il est possible d’inviter un utilisateur dans un ou plusieurs groupes secondaires avec les options -a et -G.
Exemple :
[root]# usermod -aG GroupeP,GroupeC albertLa commande usermod agit en modification et non en ajout.
Pour un utilisateur invité dans un groupe par l’intermédiaire de cette commande et déjà positionné comme invité dans d’autres groupes secondaires, il faudra indiquer dans la commande de gestion de groupe tous les groupes dont il fait partie sinon il disparaîtra de ceux-ci.
L’option -a modifie ce comportement.
Exemples :
-
Invite
albertdans le groupeGroupeP
[root]# usermod -G GroupeP albert-
Invite
albertdans le groupeGroupeG, mais le supprime de la liste des invités deGroupeP.
[root]# usermod -G GroupeG albert-
Donc soit :
[root]# usermod -G GroupeP,GroupeG albert
-
Soit :
[root]# usermod -aG GroupeG albert
Commande userdel
La commande userdel permet de supprimer le compte d’un utilisateur.
[root]# userdel -r carine| Option | Description |
|---|---|
|
Supprime le répertoire de connexion et les fichiers contenus. |
|
Pour être supprimé, un utilisateur doit être déconnecté et ne pas avoir de processus en cours. |
userdel supprime la ligne de l’utilisateur dans les fichiers /etc/passwd et /etc/gshadow.
|
Chaque utilisateur possède un |
|
Un utilisateur est obligatoirement membre d’un groupe. Il est donc nécessaire de créer les groupes avant d’ajouter les utilisateurs. |
Fichier /etc/passwd
Ce fichier contient les informations des utilisateurs (séparées par :).
[root]# head -1 /etc/passwd
root:x:0:0:root:/root:/bin/bash
(1)(2)(3)(4)(5) (6) (7)| 1 |
Login. |
| 2 |
Mot de passe (x si défini dans /etc/shadow). |
| 3 |
UID. |
| 4 |
GID du groupe principal. |
| 5 |
Commentaire. |
| 6 |
Répertoire de connexion. |
| 7 |
Interpréteur de commandes. |
Fichier /etc/shadow
Ce fichier contient les informations de sécurité des utilisateurs (séparées par :).
[root]# tail -1 /etc/shadow
root:$6$...:15399:0:99999:7:::
(1) (2) (3) (4) (5) (6)(7,8,9)| 1 |
Login. |
| 2 |
Mot de passe chiffré. |
| 3 |
Date du dernier changement. |
| 4 |
Durée de vie minimale du mot de passe. |
| 5 |
Durée de vie maximale du mot de passe. |
| 6 |
Nombre de jours avant avertissement. |
| 7 |
Délai avant désactivation du compte après expiration. |
| 8 |
Délai d’expiration du compte. |
| 9 |
Réservé pour une utilisation future. |
|
Pour chaque ligne du fichier |
Propriétaires des fichiers
|
Tous les fichiers appartiennent forcément à un utilisateur et à un groupe. |
Le groupe principal de l’utilisateur qui crée le fichier est, par défaut, le groupe propriétaire du fichier.
Commandes de modifications :
Commande chown
La commande chown permet de modifier les propriétaires d’un fichier.
chown [-R] [-v] login[:groupe] fichierExemples :
[root]# chown root fichier
[root]# chown albert:GroupeA fichier| Option | Description |
|---|---|
|
Modifie les propriétaires du répertoire et de son contenu. |
|
Affiche les modifications exécutées. |
Pour ne modifier que l’utilisateur propriétaire :
[root]# chown albert fichierPour ne modifier que le groupe propriétaire :
[root]# chown :GroupeA fichierModification de l’utilisateur et du groupe propriétaire :
[root]# chown albert:GroupeA fichierDans l’exemple suivant le groupe attribué sera le groupe principal de l’utilisateur précisé.
[root]# chown albert: fichierCommande chgrp
La commande chgrp permet de modifier le groupe propriétaire d’un fichier.
chgrp [-R] [-v] groupe fichierExemple :
[root]# chgrp groupe1 fichier| Option | Description |
|---|---|
|
Modifie les groupes propriétaires du répertoire et de son contenu (récursivité). |
|
Affiche les modifications exécutées. |
|
Il est possible d’appliquer à un fichier un propriétaire et un groupe propriétaire en prenant comme référence ceux d’un autre fichier : Par exemple : |
Gestion des invités
Commande gpasswd
La commande gpasswd permet de gérer un groupe.
gpasswd [-a login] [-A login] [-d login] [-M login] groupeExemples :
[root]# gpasswd -A alain GroupeA
[alain]$ gpasswd -a patrick GroupeA| Option | Description |
|---|---|
|
Ajoute l’utilisateur au groupe. |
|
Définit l’administrateur du groupe. |
|
Retire l’utilisateur du groupe. |
|
Définit la liste exhaustive des invités. |
La commande gpasswd -M agit en modification et non en ajout.
# gpasswd GroupeA
New Password :
Re-enter new password :Commande id
La commande id affiche les noms des groupes d’un utilisateur.
id loginExemple :
[root]# id alain
uid=500(alain) gid=500(GroupeA) groupes=500(GroupeA),516(GroupeP)Commande newgrp
La commande newgrp permet d’utiliser temporairement un groupe secondaire pour la création de fichiers.
newgrp [groupesecondaire]Exemple :
[alain]$ newgrp GroupeB|
Après utilisation de cette commande, les fichiers seront créés avec le La commande |
Sécurisation
Commande passwd
La commande passwd permet de gérer un mot de passe.
passwd [-d] [-l] [-S] [-u] [login]Exemples :
[root]# passwd -l albert
[root]# passwd -n 60 -x 90 -w 80 -i 10 patrick| Option | Description |
|---|---|
|
Supprime le mot de passe. |
|
Verrouille le compte. |
|
Affiche le statut du compte. |
|
Déverrouille le compte. |
|
Fait expirer le mot de passe. |
|
Durée de vie minimale du mot de passe. |
|
Durée de vie maximale du mot de passe. |
|
Délai d’avertissement avant expiration. |
|
Délai avant désactivation lorsque le mot de passe expire. |
Avec la commande passwd, le verrouillage d’un compte se traduit par l’ajout de !! devant le mot de passe dans le fichier /etc/shadow.
L’utilisation de la commande usermod -U ne supprime qu’un seul des !. Le compte reste donc verrouillé.
Exemple :
-
Alain change son mot de passe :
[alain]$ passwd-
root change le mot de passe d’Alain :
[root]# passwd alain
|
La commande |
Ils devront se soumettre aux restrictions de sécurité.
Lors d’une gestion des comptes utilisateurs par script shell, il peut être utile de définir un mot de passe par défaut après avoir créé l’utilisateur.
Ceci peut se faire en passant le mot de passe à la commande passwd.
Exemple :
[root]# echo "azerty,1" | passwd --stdin philippe|
Le mot de passe est saisi en clair, |
Commande chage
La commande chage permet de gérer la stratégie de compte.
chage [-d date] [-E date] [-I jours] [-l] [-m jours] [-M jours] [-W jours] [login]Exemple :
[root]# chage -m 60 -M 90 -W 80 -I 10 alain| Option | Description |
|---|---|
|
Délai avant désactivation, mot de passe expiré ( |
|
Affiche le détail de la stratégie ( |
|
Durée de vie minimale du mot de passe. |
|
Durée de vie maximale du mot de passe. |
|
Dernière modification du mot de passe. |
|
Date d’expiration du compte. |
|
Délai d’avertissement avant expiration. |
La commande chage propose également un mode interactif.
L’option -d force la modification du mot de passe à la connexion.
Exemples :
[root]# chage philippe
[root]# chage -d 0 philippe|
En l’absence d’utilisateur précisé, la commande concernera l’utilisateur qui la saisit. |
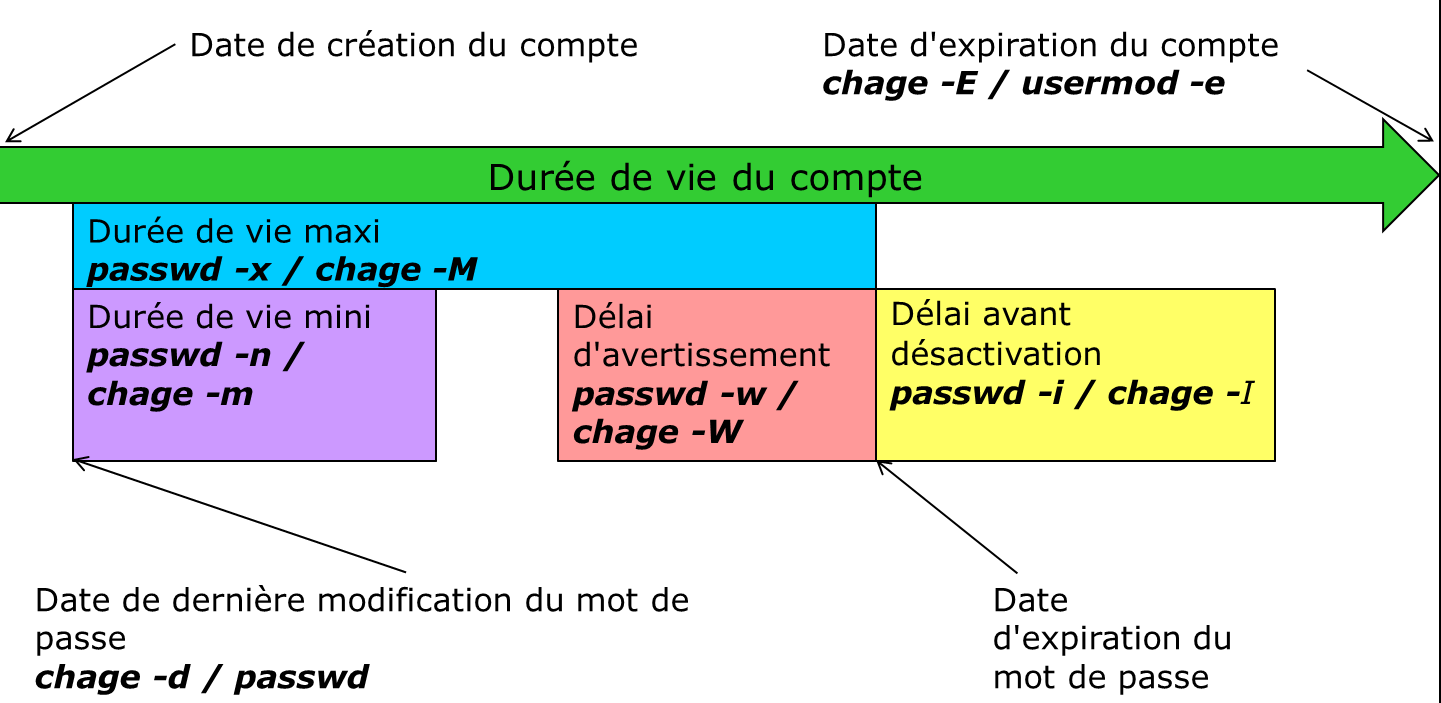
Gestion avancée
Fichiers de configuration :
-
/etc/default/useradd -
/etc/login.defs -
/etc/skel
|
L’édition du fichier |
Les autres fichiers sont à modifier avec un éditeur de texte.
Fichier /etc/default/useradd
Ce fichier contient le paramétrage des données par défaut.
|
Lors de la création d’un utilisateur, si les options ne sont pas précisées, le système utilise les valeurs par défaut définies dans |
Ce fichier est modifié par la commande useradd -D (useradd -D saisie sans autre option affiche le contenu du fichier /etc/default/useradd).
| Valeur | Commentaire |
|---|---|
|
Groupe par défaut. |
|
Chemin dans lequel le répertoire de connexion du nom de l’utilisateur sera créé. |
|
Nombre de jours suivant l’expiration du mot de passe avant que le compte ne soit désactivé. |
|
Date d’expiration du compte. |
|
Interpréteur de commandes. |
|
Répertoire squelette du répertoire de connexion. |
|
Création de la boîte aux lettres dans |
|
Sans l’option |
Pour que la commande useradd récupère la valeur du champ GROUP du fichier /etc/default/useradd, il faut préciser l’option -N.
Exemple :
[root]# useradd -u 501 -N GroupeAFichier /etc/login.defs
Ce fichier contient de nombreux paramètres par défaut utiles aux commandes de création ou de modification d’utilisateurs. Ces informations sont regroupées par paragraphe en fonction de leur utilisation :
-
Boites aux lettres ;
-
Mots de passe ;
-
UID et GID ;
-
Umask ;
-
Connexions ;
-
Terminaux.
Fichier /etc/skel
Lors de la création d’un utilisateur, son répertoire personnel et ses fichiers d’environnement sont créés.
Ces fichiers sont copiés automatiquement à partir du répertoire /etc/skel.
-
.bash_logout -
.bash_profile -
.bashrc
Tous les fichiers et répertoires placés dans ce répertoire seront copiés dans l’arborescence des utilisateurs lors de leur création.
Changement d’identité
Commande su
La commande su permet de modifier l’identité de l’utilisateur connecté.
su [-] [-c commande] [login]Exemples :
[root]# su - alain
[albert]$ su -c "passwd alain"| Option | Description |
|---|---|
|
Charge l’environnement complet de l’utilisateur. |
|
Exécute la commande sous l’identité de l’utilisateur. |
Si le login n’est pas spécifié, ce sera root.
Les utilisateurs standards devront taper le mot de passe de la nouvelle identité.
|
Il y a création de 'couches' successives (un empilement d’environnement |
Chargement du profil
root endosse l’identité de l’utilisateur alain avec su :
...
/home/GroupeA/alain/bash_rc
/etc/bashrc
...root endosse l’identité de l’utilisateur alain avec su - :
...
/home/GroupeA/alain/bash_profile
/home/GroupeA/alain/bash_rc
/etc/bashrc
...Un utilisateur peut endosser temporairement (pour une autre commande ou une session entière) l’identité d’un autre compte.
Si aucun utilisateur n’est précisé, la commande concernera root (su -).
Il est nécessaire de connaître le mot de passe de l’utilisateur dont l’identité est endossé sauf si c’est root qui exécute la commande.
Un administrateur peut ainsi travailler sur un compte utilisateur standard et n’utiliser les droits du compte root que ponctuellement.
Système de fichiers
Partitionnement
Le partitionnement va permettre l’installation de plusieurs systèmes d’exploitation car il est impossible d’en faire cohabiter plusieurs sur un même lecteur logique. Le partitionnement permet également de cloisonner des données (sécurité, optimisation d’accès, …).
Le découpage du disque physique en volumes partitionnés est inscrit dans la table des partitions stockée dans le premier secteur du disque (MBR : Master Boot Record).
Un même disque physique peut être découpé en 4 partitions maximum :
-
Primaire (ou principale)
-
Étendue
|
Il ne peut y avoir qu’une seule partition étendue par disque physique. Afin de bénéficier de lecteur supplémentaire, la partition étendue peut être découpée en partitions logiques |
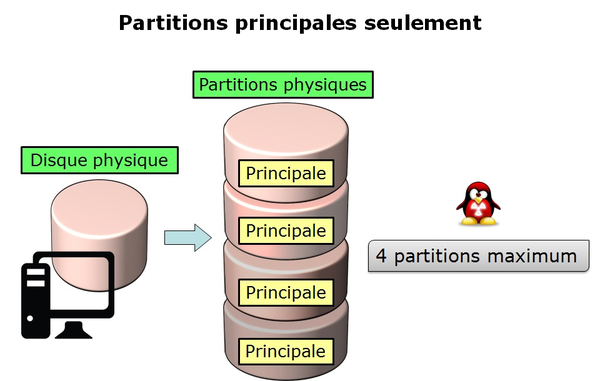
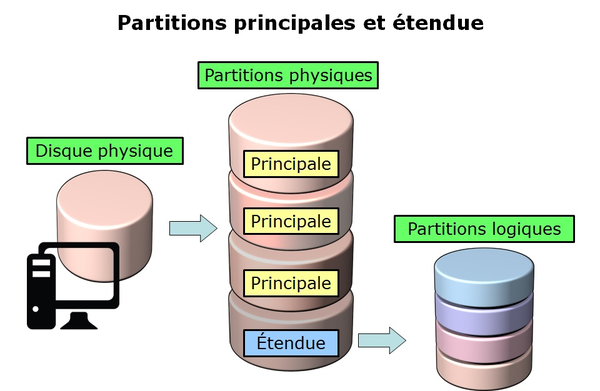
Les devices, ou périphériques, sont les fichiers identifiant les différents matériels détectés par la carte mère. Ces fichiers sont stockés sans /dev. Le service qui détecte les nouveaux périphériques et leur donne des noms s’appelle “udev”.
Ils sont identifiés en fonction de leur type.
Les périphériques de stockage se nomment hd pour les disques durs IDE et sd pour les autres supports. Vient ensuite une lettre qui commence par a pour le premier périphérique, puis b, c, …
Enfin nous allons trouver un chiffre qui définit le volume partitionné : 1 pour la première partition primaire, …
|
Attention, la partition étendue, qui ne supporte pas de système de fichier, porte quand même un numéro. |
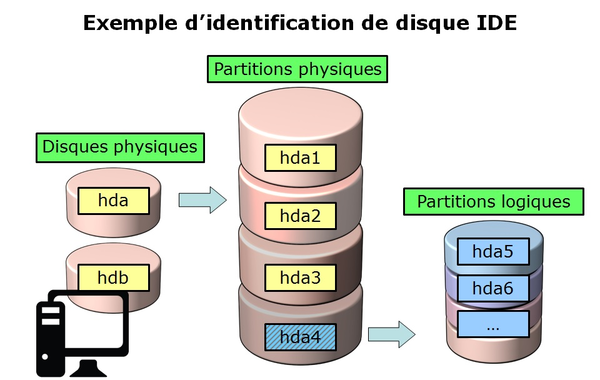
Il existe deux commandes permettant le partitionnement d’un disque : fdisk et cfdisk. Ces deux commandes possèdent un menu interactif. cfdisk étant plus fiable et mieux optimisée, il est préférable de l’utiliser.
La seule raison d’utiliser fdisk est lorsqu’on souhaite lister tous les périphériques logiques avec l’option -l.
[root]# fdisk -l
[root]# fdisk -l /dev/sdc
[root]# fdisk -l /dev/sdc2Commande parted
La commande parted indexterm[parted] (partition editor) est capable de partitionner un disque.
parted [-l] [device]Elle dispose également d’une fonction de récupération capable de réécrire une table partition effacée.
|
La fonctionnalité de redimensionnement des partitions a été supprimé avec la version 2.4. |
Sous interface graphique, il existe l’outil très complet gparted : *G*nome *PAR*tition *ED*itor. indexterm[gparted]
La commande parted -l permet de lister tous les périphériques logiques d’un ordinateur.
La commande parted exécutée seule renverra vers un mode interactif avec ses propres options internes :
-
helpou une commande incorrecte affichera ces options. -
print alldans ce mode aura le même résultat queparted –len ligne de commande. -
quitpour revenir sur le prompt
Commande cfdisk
La commande cfdisk permet de gérer les partitions
cfdisk deviceExemple :
[root]# cfdisk /dev/sda
cfdisk (util-linux-ng 2.17.2)
Unité disque : /dev/sda
Taille: 10737418240 octets, 10.7 Go
Têtes: 255 Secteurs par piste: 63 Cylindres: 1305
Nom Fanions Part Type Sys.Fic Étiq. Taille
----------------------------------------------
...
[aide] [nouvelle] [afficher] [quitter] [unités] [ecrire]La préparation, sans LVM, du support physique passe par cinq étapes :
-
Mise en place du disque physique ;
-
Partitionnement des volumes (découpage géographique du disque, possibilité d’installer plusieurs systèmes, …) ;
-
Création des systèmes de fichiers (permet au système d’exploitation de gérer les fichiers, l’arborescence, les droits, …) ;
-
Montage des systèmes de fichiers (inscription du système de fichiers dans l’arborescence) ;
-
Gérer l’accès aux utilisateurs.
Logical Volume Manager (LVM)
Logical Volume Manager (LVM)
La gestion de volume crée une couche abstraite sur un stockage physique offrant des avantages par rapport à l’utilisation directe du stockage physique :
-
Capacité du disque plus flexible ;
-
Déplacement des données en ligne ;
-
Disques en mode “stripe” (découpage) ;
-
Volumes miroirs (recopie) ;
-
Instantanés de volumes (snapshot).
L’inconvénient est que si un des volumes physiques devient HS, alors c’est l’ensemble des volumes logiques qui utilisent ce volume physique qui sont perdus. Il faudra utiliser LVM sur des disques raid.
Le LVM est disponible sous Linux à partir de la version 2.4 du noyau.
|
LVM est uniquement géré par le système d’exploitation. Par conséquent le BIOS a besoin d’au moins une partition sans LVM pour démarrer. |
Les groupes de volume
Les volumes physiques PV (issus des partitions) sont combinés en des groupes de volumes VG. Chaque VG représente un espace disque pouvant être découpé en volumes logiques LV. L’extension est la plus petite unité d’espace de taille fixe pouvant être allouée.
-
PE : Physical Extension
-
LE : Logical Extension
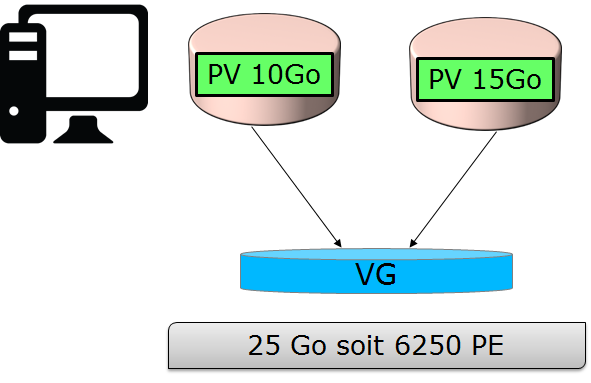
Les volumes logiques
Un groupe de volume VG est divisé en volumes logiques LV offrant différents modes de fonctionnement :
-
Volumes linéaires ;
-
Volumes en mode stripe ;
-
Volumes en miroirs.
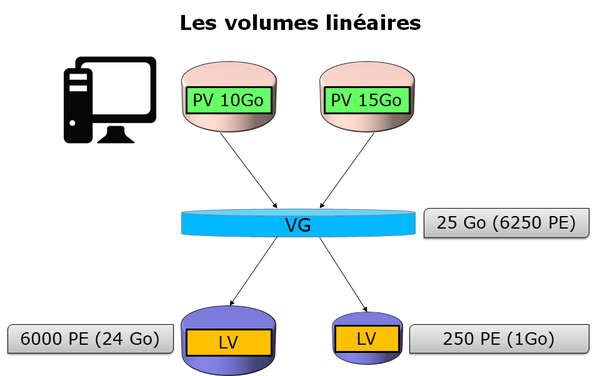
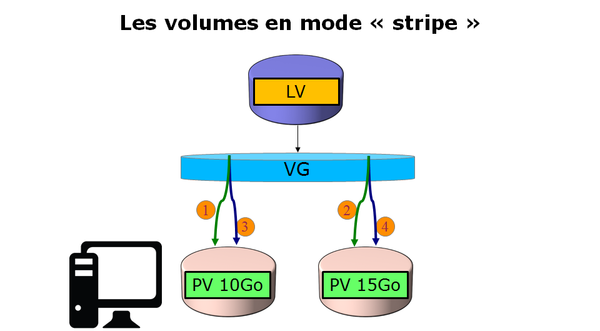
|
Le “striping” améliore les performances en écrivant des données sur un nombre prédéterminé de volumes physiques avec une technique de round-robin. |
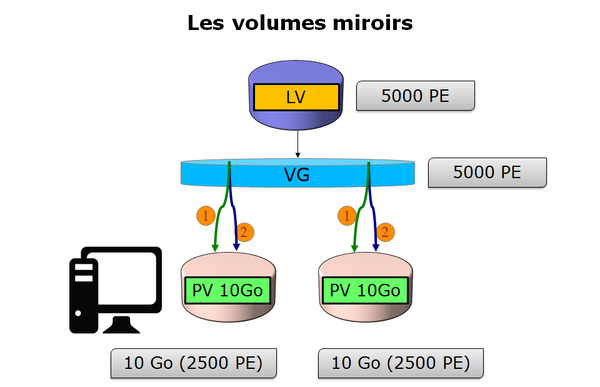
Commandes LVM pour la gestion des volumes
Commande pvcreate
La commande pvcreate permet de créer des volumes physiques. Elle transforme des partition Linux en volumes physiques.
pvcreate [-options] partitionExemple :
[root]# pvcreate /dev/hdb1
pvcreate -- physical volume « /dev/hdb1 » successfuly created| Option | Description |
|---|---|
-f |
Force la création du volume (disque déjà transformé en volume physique). |
Commande vgcreate
La commande vgcreate permet de créer des groupes de volumes. Elle regroupe un ou plusieurs volumes physiques dans un groupe de volumes.
vgcreate volume physical_volume [PV...]Exemple :
[root]# vgcreate volume1 /dev/hdb1
…
vgcreate – volume group « volume1 » successfuly created and activatedCommande lvcreate
La commande lvcreate permet de créer des volumes logiques. Le système de fichiers est ensuite créé sur ces volumes logiques.
lvcreate -L taille [-n nom] nom_VGExemple :
[root]# lvcreate –L 600M –n VolLog1 volume1
lvcreate -- logical volume « /dev/volume1/VolLog1 » successfuly created| Option | Description |
|---|---|
-L taile |
Taille du volume logique en K, M ou G |
-n nom |
Nom du LV. Fichier spécial créé dans /dev/nom_volume portant ce nom |
Commandes LVM pour visualiser les informations concernant les volumes
Commande pvdisplay
La commande pvdisplay permet de visualiser les informations concernant les volumes physiques.
pvdisplay /dev/nom_PVExemple :
[root]# pvdisplay /dev/nom_PVCommande vgdisplay
La commande vgdisplay permet de visualiser les informations concernant les groupes de volumes.
vgdisplay nom_VGExemple :
[root]# vgdisplay volume1Commande lvdisplay
La commande lvdisplay permet de visualiser les informations concernant les volumes logiques.
lvdisplay /dev/nom_VG/nom_LVExemple :
[root]# lvdisplay /dev/volume1/VolLog1Préparation du support physique
La préparation avec LVM du support physique se décompose comme suit :
-
Mise en place du disque physique
-
Partitionnement des volumes
-
Volume physique LVM
-
Groupes de volumes LVM
-
Volumes logiques LVM
-
Création des systèmes de fichiers
-
Montage des systèmes de fichiers
-
Gérer l’accès aux utilisateurs
Structure d’un système de fichiers
Un système de fichiers SF peut se nommer système de gestion de fichiers SGF mais également file system FS.
Un système de fichiers est en charge des actions suivantes :
-
Sécuriser les droits d’accès et de modification des fichiers ;
-
Manipuler des fichiers : créer, lire, modifier et supprimer ;
-
Localiser les fichiers sur le disque ;
-
Gérer l’espace mémoire.
Le système d’exploitation Linux est capable d’exploiter différents systèmes de fichiers (ext2, ext3, ext4, FAT16, FAT32, NTFS, HFS, BtrFS, JFS, XFS, …).
Commande mkfs
La commande mkfs permet de créer un système de fichiers Linux.
mkfs [-t fstype] filesysExemple :
[root]# mkfs -t ext4 /dev/sda1| Option | Description |
|---|---|
-t |
Indique le type de système de fichiers à utiliser |
|
Sans système de fichiers il n’est pas possible d’utiliser l’espace disque. |
Chaque système de fichiers possède une structure qui est identique sur chaque partition. Un Bloc de Boot et un Super Bloc initialisés par le système puis une Table des Inodes et une Zone de Données initialisées par l’administrateur.
|
La seule exception est concernant la partition swap. |
Bloc de boot
Le bloc de boot occupe le premier bloc sur le disque et est présent sur toutes les partitions. Il contient le programme assurant le démarrage et l’initialisation du système et n’est donc renseigné que pour la partition de démarrage.
Super bloc
La taille de la table du super bloc est définie à la création. Il est présent sur chaque partition et contient les éléments nécessaires à l’exploitation de celle-ci.
Il décrit le Système de Fichiers :
-
Nom du Volume Logique ;
-
Nom du Système de Fichiers ;
-
Type du Système de Fichiers ;
-
État du Système de Fichiers ;
-
Taille du Système de Fichiers ;
-
Nombre de blocs libres ;
-
Pointeur sur le début de la liste des blocs libres ;
-
Taille de la liste des inodes ;
-
Nombre et la liste des inodes libres.
Une copie est chargée en mémoire centrale dès l’initialisation du système. Cette copie est mise à jour dès modification et le système la sauvegarde périodiquement (commande sync). Lorsque le système s’arrête, il recopie également cette table en mémoire vers son bloc.
Table des inodes
La taille de la table des inodes est définie à sa création et est stockée sur la partition. Elle se compose d’enregistrements, appelés inodes, correspondant aux fichiers créés. Chaque enregistrement contient les adresses des blocs de données constituant le fichier.
|
Un numéro d’inode est unique au sein d’un système de fichiers. |
Une copie est chargée en mémoire centrale dès l’initialisation du système. Cette copie est mise à jour dès modification et le système la sauvegarde périodiquement (commande sync). Lorsque le système s’arrête, il recopie également cette table en mémoire vers son bloc. Un fichier est géré par son numéro d’inode.
|
La taille de la table des inodes détermine le nombre maximum de fichiers que peut contenir le SF. |
Informations présentes dans la table des inodes :
-
Numéro d’inode ;
-
Type de fichier et permissions d’accès ;
-
Numéro d’identification du propriétaire ;
-
Numéro d’identification du groupe propriétaire ;
-
Nombre de liens sur ce fichier ;
-
Taille du fichier en octets ;
-
Date du dernier accès au fichier ;
-
Date de la dernière modification du fichier ;
-
Date de la dernière modification de l’inode (= création) ;
-
Tableau de plusieurs pointeurs (table de blocs) sur les blocs logiques contenant les morceaux du fichier.
Zone de données
Sa taille correspond au reste de l’espace disponible de la partition. Cette zone contient les catalogues correspondant à chaque répertoire ainsi que les blocs de données correspondant aux contenus des fichiers.
Afin de garantir la cohérence du système de fichiers, une image du super-bloc et de la table des inodes est chargée en mémoire (RAM) lors du chargement du système d’exploitation afin que toutes les opérations d’E/S se fassent à travers ces tables du système. Lorsque l’utilisateur crée ou modifie des fichiers, c’est en premier lieu cette image mémoire qui est actualisée. Le système d’exploitation doit donc régulièrement actualiser le super-bloc du disque logique (commande sync).
Ces tables sont inscrites sur le disque dur lors de l’arrêt du système.
|
En cas d’arrêt brutal, le système de fichiers peut perdre sa cohérence et provoquer des pertes de données. |
Réparation du système de fichiers
Il est possible de vérifier la cohérence d’un système de fichiers à l’aide de la commande fsck.
En cas d’erreurs, des solutions sont proposées afin de réparer les incohérences. Après réparation, les fichiers restant sans entrées dans la table des inodes sont rattachés au dossier /lost+found du lecteur logique.
Commande fsck
La commande fsck est un outil en mode console de contrôle d’intégrité et de réparation pour les systèmes de fichiers Linux.
fsck [-sACVRTNP] [ -t fstype ] filesysExemple :
[root]# fsck /dev/sda1Pour vérifier la partition racine, il est possible de créer un fichier forcefsck et de redémarrer ou de faire un shutdown avec l’option -F.
[root]# touch /forcefsck
[root]# reboot
ou
[root]# shutdown –r -F now|
La partition devant être vérifiée doit impérativement être démontée. |
Organisation d’un système de fichiers
Par définition, un Système de Fichiers est une structure arborescente de répertoires construite à partir d’un répertoire racine (un périphérique logique ne peut contenir qu’un seul système de fichiers).
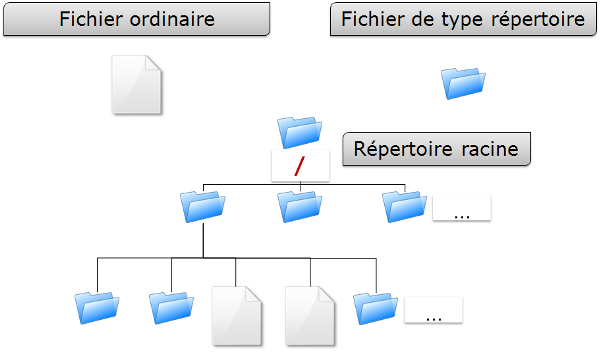
|
Sous Linux, tout est fichier. |
Document texte, répertoire, binaire, partition, ressource réseau, écran, clavier, noyau Unix, programme utilisateur, …
Linux répond à la norme FHS (Filesystems Hierarchy Standard) qui définit le nom des dossiers et leurs rôles.
| Répertoire | Observation | Abréviation |
|---|---|---|
/ |
Contient les répertoires spéciaux |
|
/boot |
Fichiers relatifs au démarrage du système |
|
/sbin |
Commandes indispensables au démarrage système |
system binaries |
/bin |
Exécutables des commandes de base du système |
binaries |
/usr/bin |
Commandes d’administration système |
|
/lib |
Librairies partagées et modules du noyau |
libraries |
/usr |
Tout ce qui n’est pas nécessaire au fonctionnement minimal du système |
UNIX System Resources |
/mnt |
Pour le montage de SF temporaires |
mount |
/media |
Pour le montage de médias amovibles |
|
/root |
Répertoire de connexion de l’administrateur |
|
/home |
Données utilisateurs |
|
/tmp |
Fichiers temporaires |
temporary |
/dev |
Fichiers spéciaux des périphériques |
device |
/etc |
Fichiers de configuration et de scripts |
editable text configuration |
/opt |
Spécifiques aux applications installées |
optional |
/proc |
Système de fichiers virtuel représentant les différents processus |
processes |
/var |
Fichiers variables divers |
variables |
Montage, démontage…quelques affirmations :
-
Pour effectuer un montage ou démontage, au niveau de l’arborescence, il ne faut pas se trouver sous le point de montage.
-
Le montage sur un répertoire non vide n’efface pas le contenu. Il est seulement masqué.
-
Seul l’administrateur peut effectuer des montages.
-
Les points de montage devant être montés automatiquement au démarrage doivent être inscrit dans /etc/fstab.
Le fichier /etc/fstab
Ce fichier est lu au démarrage du système et contient les montages à effectuer. Chaque système de fichiers à monter est décrit sur une seule ligne, les champs étant séparés pas des espaces ou des tabulations.
|
Les lignes sont lues séquentiellement (fsck, mount, umount). |
/dev/mapper/VolGroup-lv_root / ext4 defaults 1 1
UUID=46….92 /boot ext4 defaults 1 2
/dev/mapper/VolGroup-lv_swap swap swap defaults 0 0
tmpfs /dev/shm tmpfs defaults 0 0
devpts /dev/pts devpts gid=5,mode=620 0 0
sysfs /sys sysfs defaults 0 0
proc /proc proc defaults 0 0
1 2 3 4 5 6| Champ | Description |
|---|---|
1 |
Périphérique du système de fichiers (/dev/sda1, UUID=…, …) |
2 |
Nom du point de montage, chemin absolu (excepté swap) |
3 |
Type de système de fichiers (ext4, swap, …) |
4 |
Options particulières pour le montage (defaults, ro, …) |
5 |
Active ou non la gestion des sauvegardes (0:non sauvegardé, 1:sauvegardé) |
6 |
Ordre de vérification lors du contrôle du SF par la commande fsck (0:pas de contrôle, 1:prioritaire, 2:non prioritaire) |
La commande mount -a permet de prendre en compte les nouveaux montages sans redémarrage. Ils sont ensuite inscrits dans le fichier /etc/mtab qui contient les montages actuels.
|
Seuls les points de montages inscrits dans /etc/fstab seront montés au redémarrage. |
Il est possible de faire une copie du fichier /etc/mtab ou de copier son contenu vers /etc/fstab.
Commandes de gestion des montages
Commande mount
La commande mount permet de monter et de visualiser les lecteurs logiques dans l’arborescence.
mount [-option] [device] [directory]Exemple :
[root]# mount /dev/sda7 /home| Option | Description |
|---|---|
-n |
Monte sans écrire dans /etc/fstab |
-t |
Indique le type de système de fichiers à utiliser |
-a |
Monte tous les systèmes de fichiers mentionnés dans /etc/fstab |
-r |
Monte le système de fichiers en lecture seule (équivalent -o ro) |
-w |
Monte le système de fichiers en lecture/écriture, par défaut (équivalent -o rw) |
-o |
Argument suivi d’une liste d’option(s) séparée(s) par des virgules (remount, ro, …) |
|
La commande mount seule permet de visualiser tous les systèmes de fichiers montés. |
Commande umount
La commande umount permet de démonter les lecteurs logiques.
umount [-option] [device] [directory]Exemple :
[root]# umount /home
[root]# umount /dev/sda7| Option | Description |
|---|---|
-n |
Démonte sans écrire dans /etc/fstab |
-r |
Si le démontage échoue, remonte en lecture seule |
-f |
Force le démontage |
-a |
Démonte tous les systèmes de fichiers mentionnés dans /etc/fstab |
|
Pour le démontage, il ne faut pas rester en dessous du point de montage. Sinon, le message d’erreur suivant s’affiche : “device is busy”. |
Types de fichiers
Comme dans tout système, afin de pouvoir se retrouver dans l’arborescence et la gestion des fichiers, il est important de respecter des règles de nommage des fichiers.
-
Les fichiers sont codés sur 255 caractères ;
-
Tous les caractères ASCII sont utilisables ;
-
Les majuscules et minuscules sont différenciées ;
-
Pas de notion d’extension.
Les groupes de mots séparés par des espaces doivent être encadrés par des guillemets :
[root]# mkdir "repertoire travail"|
Le . sert seulement à cacher un fichier quand il débute le nom. |
|
Sous Linux, la notion d’extension n’existe pas. Cependant, elle peut être utilisée mais fait alors partie intégrante du nom du fichier. |
Exemples de conventions d’extension :
-
.c : fichier source en langage C ;
-
.h : fichier d’en-tête C et Fortran ;
-
.o : fichier objet en langage C ;
-
.tar : fichier de données archivées avec l’utilitaire tar ;
-
.cpio : fichier de données archivées avec l’utilitaire cpio ;
-
.gz : fichier de données compressées avec l’utilitaire gzip ;
-
.html : page web.
Détails du nom d’un fichier
[root]# ls -liah /usr/bin/passwd
18 -rwxr-xr-x. 1 root root 26K 22 févr. 2012 /usr/bin/passwd
1 2 3 4 5 6 7 8 9| Champ | Description |
|---|---|
1 |
Numéro d’inode |
2 |
Type de fichiers |
3 |
Droits d’accès |
4 |
Nombre de liens (ordinaire) ou sous-répertoires (répertoires) |
5 |
Nom du propriétaire |
6 |
Nom du groupe |
7 |
Taille (octet, kilo, méga) |
8 |
Date de la dernière mise à jour |
9 |
Nom du fichier |
Différents types de fichiers
On retrouve sur un système les types de fichiers suivants :
-
Ordinaires (textes, binaires, …) ;
-
Répertoires ;
-
Spéciaux (imprimantes, écrans, …) ;
-
Liens ;
-
Communications (tubes et socket).
Fichiers ordinaires
Ce sont des fichiers textes, programmes (sources), exécutables (après compilation) ou fichiers de données (binaires, ASCII) et multimédias.
[root]# ls -l fichier
-rwxr-xr-x 1 root root 26 nov 31 15:21 fichierLe tiret - au début du groupe de droits indique qu’il s’agit d’un fichier de type ordinaire.
Fichiers répertoires
Les fichiers de type répertoire contiennent des références à d’autres fichiers.
Par défaut dans chaque répertoire sont présents . et .. .
Le . représente la position dans l’arborescence.
Le .. représente le père de la position courante.
[root]# ls -l repertoire
drwxr-xr-x 1 root root 26 nov 31 15:21 repertoireLa lettre d au début du groupe de droits indique qu’il s’agit d’un fichier de type répertoire.
Fichiers spéciaux
Afin de communiquer avec les périphériques (disques durs, imprimantes, …), Linux utilise des fichiers d’interface appelés fichiers spéciaux (device file ou special file). Ils permettent donc d’identifier les périphériques.
Ces fichiers sont particuliers car ils ne contiennent pas de données mais spécifient le mode d’accès pour communiquer avec le périphérique.
Ils sont déclinés en deux modes :
-
mode bloc ;
-
mode caractère.
Le fichier spécial mode bloc permet en utilisant les buffers système de transférer des données vers le périphérique.
[root]# ls -l /dev/sda
brw------- 1 root root 8, 0 jan 1 1970 /dev/sdaLa lettre b au début du groupe de droits indique qu’il s’agit d’un fichier spécial bloc.
Le fichier spécial mode caractère est utilisé pour transférer des données vers le périphérique sous forme de flux un caractère à la fois sans utiliser de buffer. Ce sont les périphériques comme l’imprimante, l’écran ou les bandes DAT, …
La sortie standard est l’écran.
[root]# ls -l /dev/tty0
crw------- 1 root root 8, 0 jan 1 1970 /dev/tty0La lettre c au début du groupe de droits indique qu’il s’agit d’un fichier spécial caractère.
Fichiers de communication
Il s’agit des fichiers tubes (pipes) et des fichiers sockets.
Les fichiers tubes passent les informations entre processus par FIFO (First In First Out). Un processus écrit de informations transitoires dans un fichier pipe et un autre les lit. Après lecture, les informations ne sont plus accessibles.
Les fichiers sockets permettent la communication bidirectionnelle inter-processus (sur système local ou distant). Ils utilisent un inode du système de fichiers.
Fichiers liens
Ces fichiers donnent la possibilité de donner plusieurs noms logiques à un même fichier physique. Un nouveau point d’accès au fichier est par conséquent créé.
On distingue deux types de fichiers lien :
-
Les liens physiques ;
-
Les liens symboliques.
Le lien physique
Le fichier lien et le fichier source ont le même numéro d’inode et le compteur de lien est incrémenté. Il est impossible de lier des répertoires et des fichiers de système de fichiers différents.
|
Si le fichier source est détruit, le compteur est décrémenté et le fichier lien accède toujours au fichier. |
La commande ln permet de créer des liens
[root]# ls –li lettre
666 –rwxr--r-- 1 root root … lettre
[root]# ln /home/paul/lettre /home/jack/lire
[root]# ls –li /home/*/l*
666 –rwxr--r-- 2 root root … lettre
666 –rwxr--r-- 2 root root … lire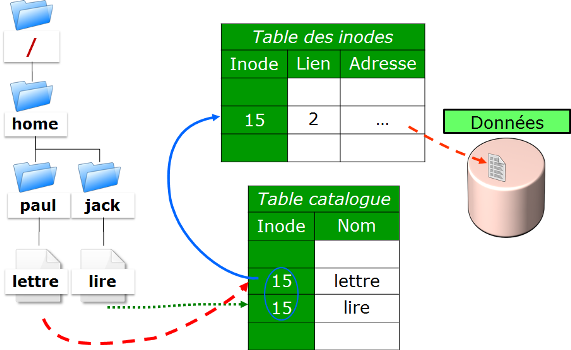
Le lien symbolique
Contrairement au lien physique, le lien symbolique implique la création d’un nouvel inode. Au niveau du lien symbolique, seul un chemin d’accès est stocké dans la table des inodes.
Le fichier créé ne contient qu’une indication sur le chemin permettant d’atteindre le fichier. Cette notion n’a plus les limitations des liens physiques et il est désormais possible de lier des répertoires et des fichiers appartenant à des systèmes de fichiers différents.
|
Si le fichier source est détruit, le fichier lien ne peut plus accéder au fichier. |
[root]# ls –li lettre
666 –rwxr--r--- 1 root root … lettre
[root]# ln –s /home/paul/lettre /tmp/lire
[root]# ls –li /home/paul/lettre /tmp/lire
666 –rwxr--r--- 1 root root … lettre
678 lrwxrwxrwx 1 root root … lire -> lettre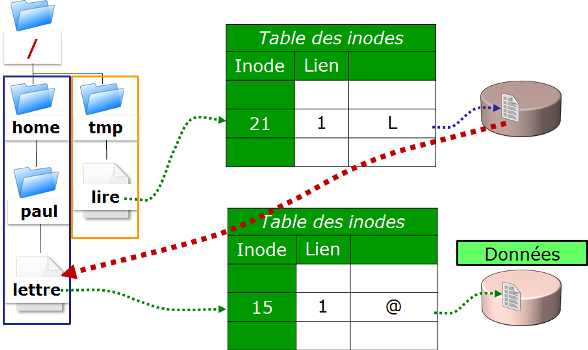
Attributs des fichiers
Linux est système d’exploitation multi-utilisateurs où l’accès aux fichiers est contrôlé.
Ces contrôles sont fonctions :
-
des permissions d’accès au fichier ;
-
des utilisateurs (ugo).
La commande ls -l permet afficher les attributs.
Il existe 4 droits d’accès aux fichiers :
-
read (lecture) ;
-
write (écriture) ;
-
execution (exécution) ;
-
- aucun droit.
|
Les droits associés aux fichiers diffèrent de ceux associés aux répertoires (voir ci-dessous). |
Les types d’utilisateurs associés aux droits d’accès des fichiers sont :
-
user (propriétaire) ;
-
group (groupe propriétaire) ;
-
others (les autres) ;
Dans certaines commandes, il est possible de désigner tout le monde avec a (all).
a = ugo
Droits associés aux fichiers ordinaires
-
read : Permet la lecture d’un fichier (cat, less, …) et autorise la copie (cp, …).
-
write : Autorise la modification du contenu du fichier (cat, », vim, …).
-
execute : Considère le fichier comme une commande (binaire, script).
-
- : Aucune permission.
|
Déplacer ou renommer un fichier dépend des droits du répertoire cible. Supprimer un fichier dépend des droits du répertoire parent. |
Droits associés aux répertoires
-
read : Permet la lecture du contenu d’un répertoire (ls -R).
-
write : Autorise la modification du contenu d’un répertoire (touch) et permet la création et suppression de fichiers si la permission x est activée.
-
execute : Permet de descendre dans le répertoire (cd).
-
- : Aucun droit.
Gestion des attributs
L’affichage des droits se fait à l’aide de la commande ls -l
[root]# ls -l /tmp/fichier
-rwxrw-r-x 1 root sys ... /tmp/fichier
1 2 3 4 5| Champ | Description |
|---|---|
1 |
Permissions du propriétaire (user), ici rwx |
2 |
Permissions du groupe propriétaire (group), ici rw- |
3 |
Permissions des autres utilisateurs (others), ici r-x |
4 |
Propriétaire du fichier |
5 |
Groupe propriétaire du fichier |
|
Les permissions s’appliquent sur user, group et other (ugo) en fonction du propriétaire et du groupe. |
Par défaut, le propriétaire d’un fichier est celui qui le crée. Le groupe du fichier est le groupe du propriétaire qui a créé le fichier. Les autres sont ceux qui ne sont pas concernés par les cas précédents.
La modification des attributs s’effectue à l’aide de la commande chmod
Seuls l’administrateur et le propriétaire d’un fichier peuvent modifier les droits d’un fichier.
Commande chmod
La commande chmod permet de modifier les autorisations d’accès à un fichier.
chmod [option] mode fichierL’indication de mode peut être une représentation octale (ex : 744) ou une représentation symbolique ([ugoa][+=-][rwxst]).
Plusieurs opérations symboliques peuvent être séparées par des virgules
Exemple :
[root]# chmod -R u+rwx,g+wx,o-r /tmp/fichier1
[root]# chmod g=x,o-r /tmp/fichier2
[root]# chmod -R o=r /tmp/fichier3
[root]# ls -l /tmp/fic*
-rwxrwx--- 1 root root … /tmp/fichier1
-rwx--x--- 1 root root … /tmp/fichier2
-rwx--xr-- 1 root root … /tmp/fichier3[root]# chmod 741 /tmp/fichier1
[root]# chmod -R 744 /tmp/fichier2
[root]# ls -l /tmp/fic*
-rwxr----x 1 root root … /tmp/fichier1
-rwxr--r-- 1 root root … /tmp/fichier2| Option | Observation |
|---|---|
-R |
Modifier récursivement les autorisations des répertoires et de leurs contenus |
Il existe deux méthodes pour effectuer les changements de droits :
-
La méthode octale ;
-
La méthode symbolique.
|
Les droits des fichiers et des répertoires ne sont pas dissociés. Pour certaines opérations, il faudra connaître les droits du répertoire contenant le fichier. Un fichier protégé en écriture peut être supprimé par un autre utilisateur dans la mesure où les droits du répertoire qui le contient autorisent cet utilisateur à effectuer cette opération. |
Principe de la méthode octale
Chaque droit possède une valeur.
[root]# ls -l /tmp/fichier
-rwxrwxrwx 1 root root ... /tmp/fichier
[root]# chmod 741 /tmp/fichier
-rwxr----x 1 root root ... /tmp/fichier
Principe de la méthode symbolique
Cette méthode peut être considérée comme une association “littérale” entre un type d’utilisateur, un opérateur et des droits.

[root]# chmod u+rwx,g+wx,o-r /tmp/fichier
[root]# chmod g=x,o-r /tmp/fichier
[root]# chmod o=r /tmp/fichier[root]# ls -l /tmp/fichier
----r--r-- 1 root root … /tmp/fichier
[root]# chmod u+rwx,g+wx,o-r /tmp/fichier
[root]# ls -l /tmp/fichier
-rwxrwx--- 1 root root … /tmp/fichierLes droits particuliers
En complément des droits fondamentaux (rwx), il existe les droits particuliers :
-
set-user-ID (SUID)
-
set-group-ID (SGID)
-
sticky-bit
Comme pour les droits fondamentaux, les droits particuliers possèdent chacun une valeur. Celle-ci se place avant l’ensemble de droits ugo.
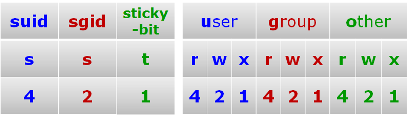
|
S, S et T en majuscules si le droit n’existe pas. |
Le Sticky-bit
Une des particularités des droits sous Linux est que le droit d’écrire sur un répertoire permet également de supprimer tous les fichiers, propriétaire ou non.
Le sticky-bit positionné sur le répertoire ne permettra aux utilisateurs d’effacer que les fichiers dont ils sont propriétaires.
La mise en place du sticky-bit peut s’effectuer comme ci-dessous :
Méthode octale :
[root]# chmod 1777 repertoireMéthode symbolique :
[root]# chmod o+t repertoire[root]# ls -l
drwxrwxrwt … repertoireSUID et SGID sur une commande
Ces droits permettent d’exécuter une commande suivant les droits positionnés sur la commande et non plus suivant les droits de l’utilisateur.
La commande s’exécute avec l’identité du propriétaire (suid) ou du groupe (sgid) de la commande.
|
L’identité de l’utilisateur demandant l’exécution de la commande n’est plus prise en compte. |
Il s’agit d’une possibilité supplémentaire de droits d’accès attribués à un utilisateur lorsqu’il est nécessaire qu’il dispose des mêmes droits que ceux du propriétaire d’un fichier ou ceux du groupe concerné.
En effet, un utilisateur peut avoir à exécuter un programme (en général un utilitaire système) mais ne pas avoir les droits d’accès nécessaires. En positionnant les droits adéquats ( “s” au niveau du propriétaire et/ou au niveau du groupe), l’utilisateur du programme possède, pour le temps d’exécution de celui-ci, l’identité du propriétaire (ou celle du groupe) du programme.
Exemple :
Le fichier /usr/bin/passwd est un fichier exécutable (une commande) qui porte un SUID.
Lorsque l’utilisateur bob va le lancer, ce dernier devra accéder au fichier /etc/shadow, or les droits sur ce fichier ne permettent pas à bob d’y accéder.
Ayant un SUID cette commande sera exécutée avec l’UID de root et le GID de root. Ce dernier étant le propriétaire du fichier /etc/shadow, il aura les droits en lecture.
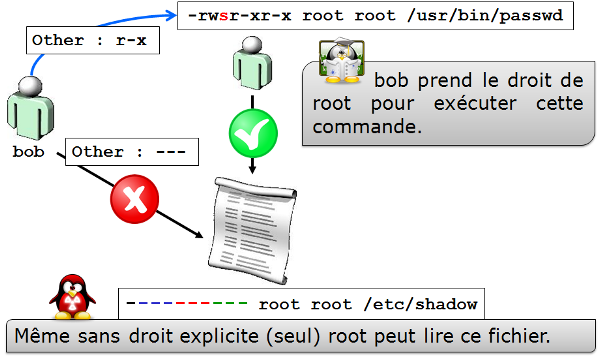
La mise en place du SUID et SGID peut s’effectuer comme ci-dessous :
Méthode octale :
[root]# chmod 4777 commande1
[root]# chmod 2777 commande2Méthode symbolique :
[root]# chmod u+s commande1
[root]# chmod g+s commande2[root]# ls -l
-rwsrwxrwx … commande1
-rwxrwsrwx … commande2|
Il n’est pas possible de transmettre le SUID ou le SGID à un script shell. Le système ne le permet pas car trop dangereux pour la sécurité! |
SGID sur un dossier
Dans un répertoire ayant le droit SGID, tout fichier créé héritera du groupe propriétaire du répertoire au lieu de celui de l’utilisateur créateur.
Exemple :
[stagiaire] $ ll -d /STAGE/
drwxrwsr-x 2 root users 4096 26 oct. 19:43 /STAGE
[stagiaire] $ touch /STAGE/test
[stagiaire] $ ll /STAGE
-rw-r--r--. 1 stagiaire users 0 26 oct. 19:43 test (1)| 1 | Le fichier test hérite du groupe propriétaire de son dossier /STAGE (ici users) quelque soit le groupe principal de l’utilisateur stagiaire. |
Droits par défaut et masque
Lors de sa création, un fichier ou un répertoire possède déjà des permissions.
-
Pour un répertoire : rwxr-xr-x soit 755
-
Pour un fichier : rw-r–r– soit 644
Ce comportement est défini par le masque par défaut.
Le principe est d’enlever la valeur définit du masque aux droits maximums.
Pour un répertoire :
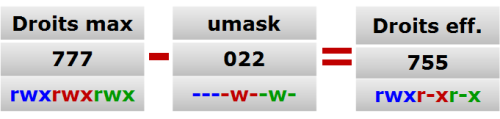
Pour un fichier, les droits d’exécution sont retirés :

Commande umask
La commande umask permet d’afficher et de modifier le masque.
umask [option] [mode]Exemple :
[root]# umask
0033
[root]# umask 025
[root]# umask
0025| Option | Description |
|---|---|
-S |
Affichage symbolique |
|
umask n’affecte pas les fichiers existants. |
|
umask modifie le masque jusqu’à la déconnexion. Pour garder la valeur, il faut modifier les fichiers de profile suivants : |
Pour tous les utilisateurs :
-
/etc/profile
-
/etc/bashrc
Pour un utilisateur en particulier :
-
~/.bashrc
Gestion des processus
Généralités
Un système d’exploitation se compose de processus. Ces derniers,sont exécutés dans un ordre bien précis et observent des liens de parenté entre eux. On distingue deux catégories de processus, ceux axés sur l’environnement utilisateur et ceux sur l’environnement matériel.
Lorsqu’un programme s’exécute, le système va créer un processus en plaçant les données et le code du programme en mémoire et en créant une pile d’exécution. Un processus est donc une instance d’un programme auquel est associé un environnement processeur (compteur ordinal, registres, etc.) et un environnement mémoire.
Chaque processus dispose :
-
d’un
PID: Process IDentifiant, identifiant unique de processus ; -
d’un
PPID: Parent Process IDentifiant, identifiant unique de processus parent.
Par filiations successives, le processus init est le père de tous les processus.
-
Un processus est toujours créé par un processus père ;
-
Un processus père peut avoir plusieurs processus fils.
Il existe une relation père / fils entre les processus, un processus fils est le résultat de l’appel système de la primitive fork() par le processus père qui duplique son propre code pour créer un fils. Le PID du fils est renvoyé au processus père pour qu’il puisse dialoguer avec. Chaque fils possède l’identifiant de son père, le `PPID.
Le numéro PID représente le processus au moment de son exécution. À la fin de celui-ci, le numéro est de nouveau disponible pour un autre processus. Exécuter plusieurs fois la même commande produira à chaque fois un PID différent.
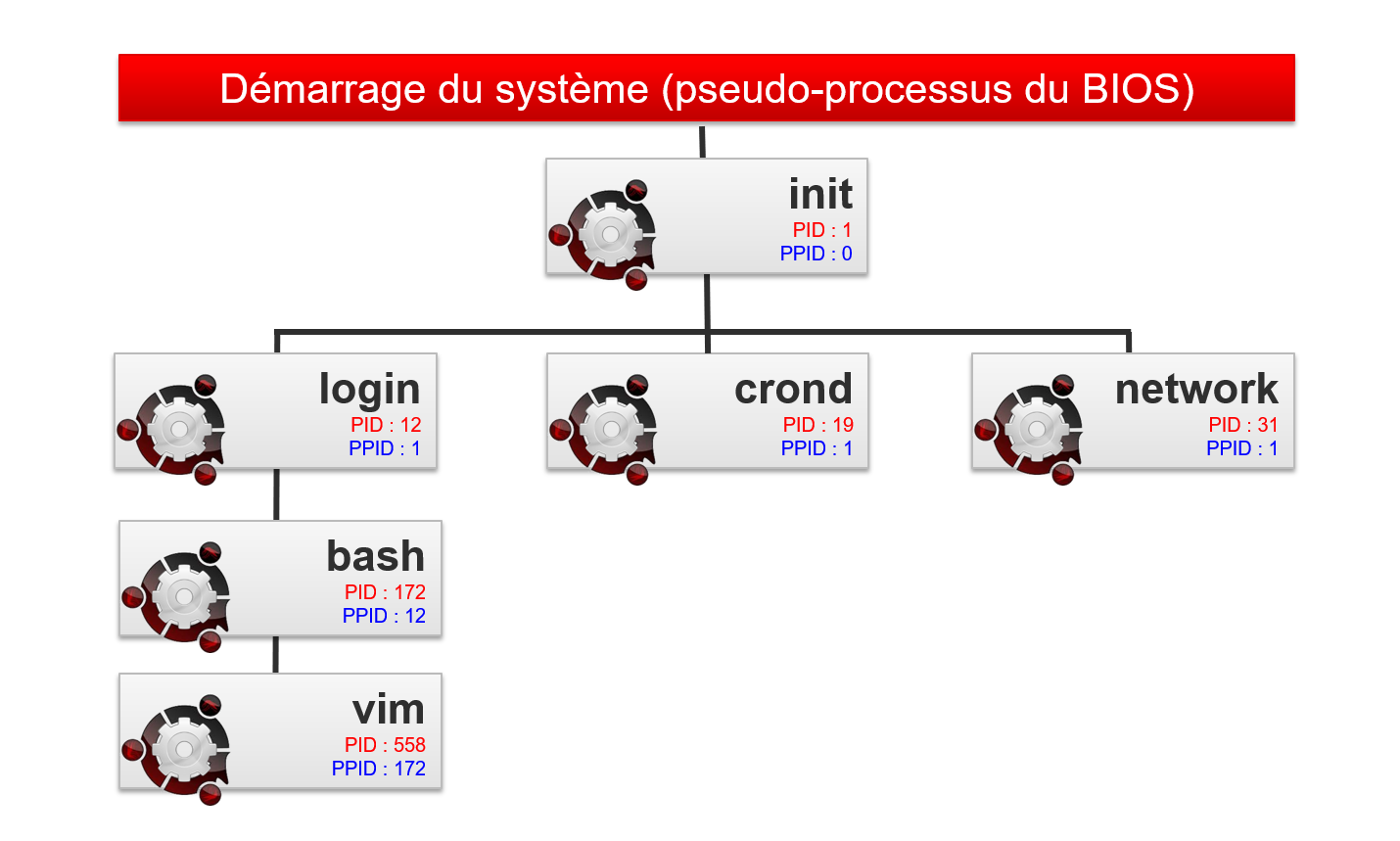
|
Les processus ne sont pas à confondre avec les threads. Chaque processus possède son propre contexte mémoire (ressources et espace d’adressage) alors que les threads issus d’un même processus partagent ce même contexte. |
Visualisation des processus
La commande ps affiche l’état des processus en cours.
ps [-e] [-f] [-u login]Exemple :
# ps -fu root| Option | Description |
|---|---|
|
Affiche tous les processus. |
|
Affiche des informations supplémentaires. |
|
Affiche les processus de l’utilisateur. |
Quelques options supplémentaires :
| Option | Description |
|---|---|
|
Affiche les processus du groupe. |
|
Affiche les processus exécutés à partir du terminal. |
|
Affiche les informations du processus. |
|
Affiche les informations sous forme d’arborescence. |
|
Affiche des informations supplémentaires. |
`--sort COL |
Trier le résultat selon une colonne. |
`--headers |
Affiche l’en-tête sur chaque page du terminal. |
|
Personnalise le format d’affichage de sortie. |
Sans option précisée, la comme ps n’affiche que les processus exécutés à partir du terminal courant.
Le résultat est affiché par colonnes :
# ps -ef
UID PID PPID C STIME TTY TIME CMD
root 1 0 0 Jan01 ? 00:00/03 /sbin/init| Colonne | Description |
|---|---|
|
Utilisateur propriétaire. |
|
Identifiant du processus. |
|
Identifiant du processus parent. |
|
Priorité du processus. |
|
Date et heure d’exécution. |
|
Terminal d’exécution. |
|
Durée de traitement. |
|
Commande exécutée. |
Le comportement de la commande peut être totalement personnalisé :
# ps -e --format "%P %p %c %n" --sort ppid --headers
PPID PID COMMAND NI
0 1 systemd 0
0 2 kthreadd 0
1 516 systemd-journal 0
1 538 systemd-udevd 0
1 598 lvmetad 0
1 643 auditd -4
1 668 rtkit-daemon 1
1 670 sssd 0Types de processus
Le processus utilisateur :
-
il est démarré depuis un terminal associé à un utilisateur ;
-
il accède aux ressources via des requêtes ou des démons.
Le processus système (démon) :
-
il est démarré par le système ;
-
il n’est associé à aucun terminal et son propriétaire est un utilisateur système (souvent
root) ; -
il est chargé lors du démarrage, il réside en mémoire et est en attente d’un appel ;
-
il est généralement identifié par la lettre
dassocié au nom du processus.
Les processus système sont donc appelés démons de l’anglais daemon (Disk And Execution MONitor).
Permissions et droits
À l’exécution d’une commande, les identifiants de l’utilisateur sont transmis au processus créé.
Par défaut, les UID et GID effectifs (du processus) sont donc identiques aux UID et GID réels (les UID et GID de l’utilisateur qui a exécuté la commande).
Lorsqu’un SUID (et/ou un SGID) est positionné sur une commande, les UID (et/ou GID) effectifs deviennent ceux du propriétaire (et/ou du groupe propriétaire) de la commande et non plus celui de l’utilisateur ou du groupe utilisateur qui a lancé la commande. UID effectifs et réels sont donc différents.
À chaque accès à un fichier, le système vérifie les droits du processus en fonction de ses identifiants effectifs.
Gestion des processus
Un processus ne peut pas être exécuté indéfiniment, cela se ferait au détriment des autres processus en cours et empêcherait de faire du multitâche.
Le temps de traitement total disponible est donc divisé en petites plages et chaque processus (doté d’une priorité) accède au processeur de manière séquencée. Le processus prendra plusieurs états au cours de sa vie parmi les états :
-
prêt : attend la disponibilité du processus ;
-
en exécution : accède au processeur ;
-
suspendu : en attente d’une E/S (entrée/sortie) ;
-
arrêté : en attente d’un signal d’un autre processus ;
-
zombie : demande de destruction ;
-
mort : le père du processus tue son fils.
Le séquencement de fin de processus est le suivant :
-
Fermeture des fichiers ouverts ;
-
Libération de la mémoire utilisée ;
-
Envoi d’un signal au processus père et aux processus fils.
Lorsqu’un processus meurt, ses processus fils sont dits orphelins. Ils sont alors adoptés par le processus init qui se chargera de les détruire.
La priorité d’un processus
Le processeur travaille en temps partagé, chaque processus occupe un quantum de temps du processeur.
Les processus sont classés par priorité dont la valeur varie de -20 (la priorité la plus élevée) à +20 (la priorité la plus basse).
La priorité par défaut d’un processus est 0.
Modes de fonctionnements
Les processus peuvent fonctionner de deux manières :
-
synchrone: l’utilisateur perd l’accès au shell durant l’exécution de la commande. L’invite de commande réapparaît à la fin de l’exécution du processus. -
asynchrone: le traitement du processus se fait en arrière-plan, l’invite de commande est ré-affichée immédiatement.
Les contraintes du mode asynchrone :
-
la commande ou le script ne doit pas attendre de saisie au clavier ;
-
la commande ou le script ne doit pas retourner de résultat à l’écran ;
-
quitter le shell termine le processus.
Les commandes de gestion des processus
La commande kill
La commande kill envoie un signal d’arrêt à un processus.
kill [-signal] PIDExemple :
$ kill -9 1664| Code | Signal | Description |
|---|---|---|
|
|
Interruption du processus (CTRL+D) |
|
|
Terminaison immédiate du processus |
|
|
Terminaison propre du processus |
|
|
Reprise du processus |
|
|
Suspension du processus |
Les signaux sont les moyens de communication entre les processus. La commande kill permet d’envoyer un signal à un processus.
|
La liste complète des signaux pris en compte par la commande |
La commande nohup
La commande nohup permet de lancer un processus indépendant d’une connexion.
nohup commandeExemple :
$ nohup MonProgramme.sh 0</dev/null &nohup ignore le signal SIGHUP envoyé lors de la déconnexion d’un utilisateur.
|
|
[CTRL] + [Z]
En appuyant simultanément sur les touches CTRL+Z, le processus synchrone est temporairement suspendu. L’accès au prompt est rendu après affichage du numéro du processus venant d’être suspendu.
Instruction &
L’instruction & exécute la commande en mode asynchrone (la commande est alors appelée job) et affiche le numéro de job. L’accès au prompt est ensuite rendu.
Exemple :
$ time ls -lR / > list.ls 2> /dev/null &
[1] 15430
$Le numéro de job est obtenu lors de la mise en tâche de fond et est affiché entre crochets, suivi du numéro de PID.
Les commandes fg et bg
La commande fg place le processus au premier plan :
$ time ls -lR / > list.ls 2>/dev/null &
$ fg 1
time ls -lR / > list.ls 2/dev/nulltandis que la commande bg le place à l’arrière plan :
[CTRL]+[Z]
^Z
[1]+ Stopped
$ bg 1
[1] 15430
$Qu’il ait été mis à l’arrière plan lors de sa création grâce à l’argument & ou plus tard avec les touches CTRL+Z, un processus peut être ramené au premier plan grâce à la commande fg et à son numéro de job.
La commande jobs
La commande jobs affiche la liste des processus tournant en tâche de fond et précise leur numéro de job.
Exemple :
$ jobs
[1]- Running sleep 1000
[2]+ Running find / > arbo.txtLes colonnes représentent :
-
le numéro de job ;
-
ordre de passage des processus
-
un
+: le processus est le prochain processus à s’exécuter par défaut avecfgoubg; -
un
-: le processus est le prochain processus qui prendra le+;
-
-
Running (en cours de traitement) ou Stopped (processus suspendu).
-
la commande
Les commandes nice/renice
La commande nice permet d’exécuter une commande en précisant sa priorité.
nice priorité commandeExemple :
$ nice -n+15 find / -name "fichier"Contrairement à root, un utilisateur standard ne peut que réduire la priorité d’un processus. Seules les valeurs entre +0 et +19 seront acceptées.
|
Cette dernière limitation peut être levée par utilisateurs ou par groupes en modifiant le fichier |
La commande renice permet de modifier la priorité d’un processus en cours d’exécution.
renice priorité [-g GID] [-p PID] [-u UID]Exemple :
$ renice +15 -p 1664
| Option | Description |
|---|---|
|
|
|
`PID du processus. |
|
|
La commande renice agit sur des processus déjà en cours d’exécution. Il est donc possible de modifier la priorité d’un processus précis, mais aussi de plusieurs processus appartenant à un utilisateur ou à un groupe.
|
La commande |
La commande top
La commande top affiche les processus et leur consommation en ressources.
$ top
PID USER PR NI ... %CPU %MEM TIME+ COMMAND
2514 root 20 0 15 5.5 0:01.14 top| Colonne | Description |
|---|---|
|
Identifiant du processus. |
|
Utilisateur propriétaire. |
|
Priorité du processus. |
|
Valeur du nice. |
|
Charge du processeur. |
|
Charge de la mémoire. |
|
Temps d’utilisation processeur. |
|
Commande exécutée. |
La commande top permet de contrôler les processus en temps réel et en mode interactif.
Les commandes pgrep et pkill
La commande pgrep cherche parmi les processus en cours d’exécution un nom de processus et affiche sur la sortie standard les PID correspondant aux critères de sélection.
La commande pkill enverra le signal indiqué (par défaut SIGTERM) à chaque processus.
pgrep processus
pkill [-signal] processusExemples :
-
Récuperer le numéro de processus de
sshd:
$ pgrep -u root sshd-
Tuer tous les processus
tomcat:
$ pkill tomcatSauvegardes et restaurations
La sauvegarde va permettre de répondre à un besoin de conservation et de restauration des données de manière sûre et efficace.
La sauvegarde permet de se protéger des éléments suivants :
-
Destruction : Volontaire ou involontaire. Humaine ou technique. Virus, …
-
Suppression : Volontaire ou involontaire. Humaine ou technique. Virus, …
-
Intégrité : Données devenues inutilisables.
Aucun système n’est infaillible, aucun humain n’est infaillible, aussi pour éviter de perdre des données, il faut les sauvegarder pour être en mesure de les restaurer suite à un problème.
Les supports de sauvegarde sont conservés dans une autre pièce (voire bâtiment) que le serveur afin qu’un sinistre ne vienne pas détruire le serveur et les sauvegardes.
De plus, l’administrateur devra régulièrement vérifier que les supports soient toujours lisibles.
Généralités
Il existe deux principes, la sauvegarde et l'archive.
-
L’archive détruit la source d’information après l’opération.
-
La sauvegarde conserve la source d’information après l’opération.
Ces opérations consistent à enregistrer des informations dans un fichier, sur un périphérique ou un support (bandes, disques, …).
La démarche
La sauvegarde nécessite de l’administrateur du système beaucoup de discipline et une grande rigueur. Il est nécessaire de se poser les questions suivantes :
-
Quel est le support approprié ?
-
Que faut-il sauvegarder ?
-
Nombre d’exemplaires ?
-
Durée de la sauvegarde ?
-
Méthode ?
-
Fréquence ?
-
Automatique ou manuelle ?
-
Où la stocker ?
-
Délai de conservation ?
Méthodes de sauvegardes
-
Complète : un ou plusieurs systèmes de fichiers sont sauvegardés (noyau, données, utilitaires, …).
-
Partielle : un ou plusieurs fichiers sont sauvegardés (configurations, répertoires, …).
-
Différentielle : uniquement les fichiers modifiés depuis la dernière sauvegarde complète sont sauvegardés.
-
Incrémentale : uniquement les fichiers modifiés depuis la dernière sauvegarde sont sauvegardés.
-
Périodicité
-
Ponctuelle : à un instant donné (avant une mise à jour du système, …).
-
Périodique : Journalière, hebdomadaire, mensuelle, …
|
Avant une modification du système, il peut être utile de faire une sauvegarde. Cependant, il ne sert à rien de sauvegarder tous les jours des données qui ne sont modifiées que tous les mois. |
Méthodes de restauration
En fonction des utilitaires disponibles, il sera possible d’effectuer plusieurs types de restaurations.
-
Restauration complète : arborescences, …
-
Restauration sélective : partie d’arborescences, fichiers, …
Il est possible de restaurer la totalité d’une sauvegarde mais il est également possible d’en restaurer uniquement une partie. Toutefois, lors de la restauration d’un répertoire, les fichiers créés après la sauvegarde ne sont pas supprimés.
|
Pour récupérer un répertoire tel qu’il était au moment de la sauvegarde il convient d’en supprimer complètement le contenu avant de lancer la restauration. |
Les outils
Il existe de nombreux utilitaires pour réaliser les sauvegardes.
-
outils éditeurs ;
-
outils graphiques ;
-
outils mode de commande : tar, cpio, pax, dd, dump, …
Les commandes que nous verrons ici sont tar et cpio.
-
tar :
-
simple d’utilisation ;
-
permet l’ajout de fichiers à une sauvegarde existante.
-
-
cpio :
-
conserve les propriétaires ;
-
groupes, dates et droits ;
-
saute les fichiers endommagés ;
-
système de fichiers complet.
-
|
Ces commandes sauvegardent dans un format propriétaire et standardisé. |
Convention de nommage
L’emploi d’une convention de nommage permet de cibler rapidement le contenu d’un fichier de sauvegarde et d’éviter ainsi des restaurations hasardeuses.
-
nom du répertoire ;
-
utilitaire employé ;
-
options utilisées ;
-
date.
|
Le nom de la sauvegarde doit être un nom explicite. |
|
La notion d’extension sous Unix n’existe pas. |
Contenu d’une sauvegarde
Une sauvegarde contient généralement les éléments suivants :
-
le fichier ;
-
le nom ;
-
le propriétaire ;
-
la taille ;
-
les permissions ;
-
date d’accès.
|
Le numéro d’inode est absent. |
Modes de stockage
Deux modes de stockage se distinguent :
-
fichier sur le disque ;
-
périphérique.
Tape ArchiveR - tar
La commande tar permet la sauvegarde sur plusieurs supports successifs (options multi-volumes).
Il est possible d’extraire tout ou partie d’une sauvegarde.
Tar sauvegarde implicitement en mode relatif même si le chemin des informations à sauvegarder est mentionné en mode absolu.
Consignes de restauration
Il faut se poser les bonnes questions
-
quoi : Partielle ou complète ;
-
où : Lieu où les données seront restaurées ;
-
comment : Absolu ou relatif.
|
Avant une restauration, il faut prendre le temps de la réflexion et déterminer la méthode la mieux adaptée afin d’éviter toutes erreurs. |
Les restaurations s’effectuent généralement après un problème qui doit être résolu rapidement. Une mauvaise restauration peut dans certains cas aggraver la situation.
La sauvegarde avec tar
L’utilitaire par défaut pour créer des archives dans les systèmes UNIX est la commande tar. Ces archives peuvent être compressées avec une compression gzip ou bzip.
Tar permet d’extraire aussi bien un seul fichier ou un répertoire d’une archive, visualiser son contenu ou valider son intégrité, etc.
Créer une archive
Créer une archive non-compressée s’effectue avec les clefs cvf :
tar c[vf] [support] [fichiers(s)]Exemple :
[root]# tar cvf /sauvegardes/home.133.tar /home/| Clef | Description |
|---|---|
c |
Crée une sauvegarde. |
v |
Affiche le nom des fichiers traités. |
f |
Permet d’indiquer le nom de la sauvegarde (support). |
|
Il n’y a pas de tiret '-' devant les clefs de tar ! |
Créer une sauvegarde en mode absolu
tar c[vf]P [support] [fichiers(s)]Exemple :
[root]# tar cvfP /sauvegardes/home.133.P.tar /home/| Clef | Description |
|---|---|
P |
Créer une sauvegarde en mode absolu. |
|
Avec la clef P, le chemin des fichiers à sauvegarder doit être renseigné en absolu. Si les deux conditions (clef P et chemin absolu) ne sont pas indiquées, la sauvegarde est en mode relatif. |
Créer une archive compressée avec gzip
Créer une archive compressée en gzip s’effectue avec les clefs cvzf :
[root]# tar cvzf archive.tar.gz dirname/| Clef | Description |
|---|---|
z |
Compresse l’archive en gzip. |
|
L’extension .tgz est une extension équivalente à .tar.gz |
|
Conserver les clefs 'cvf' ('tvf' ou 'xvf') inchangée pour toutes les manipulations d’archives et simplement ajouter à la fin des clefs celle de compression simplifie la compréhension de la commande (par exemple 'cvfz' ou 'cvfj', etc.). |
Créer une archive compressée avec bzip
Créer une archive compressée en bzip s’effectue avec les clefs cvfj :
[root]# tar cvfj archive.tar.bz2 dirname/| Clef | Description |
|---|---|
j |
Compresse l’archive en bzip2. |
|
Les extensions .tbz et .tb2 sont des extensions équivalentes à .tar.bz2 |
gzip vs bzip2
bzip2 nécessite plus de temps pour compresser ou décompresser que gzip mais offre des ratios de compression supérieurs.
Extraire (untar) une archive
Extraire (untar) une archive *.tar avec s’effectue avec les clefs xvf :
[root]# tar xvf /sauvegardes/etc.133.tar etc/exports
[root]# tar xvfj /sauvegardes/home.133.tar.bz2
[root]# tar xvfP /sauvegardes/etc.133.P.tar|
Se placer au bon endroit. Vérifier le contenu de la sauvegarde. |
| Clef | Description |
|---|---|
x |
Extrait des fichiers de l’archive, compressée ou non. |
Extraire une archive tar-gzippée (*.tar.gz) s’effectue avec les clefs xvfz
[root]# tar xvfz archive.tar.gzExtraire une archive tar-bzippée (*.tar.bz2) s’effectue avec les clefs xvfj
[root]# tar xvfj archive.tar.bz2Lister le contenu d’une archive
Visualiser le contenu d’une archive sans l’extraire s’effectue avec les clefs tvf :
[root]# tar tvf archive.tar
[root]# tar tvfz archive.tar.gz
[root]# tar tvfj archive.tar.bz2Lorsque le nombre de fichiers contenus dans une archive devient important, il est possible de passer à la commande less le résultat de la commande tar par un pipe ou en utilisant directement la commande less :
[root]# tar tvf archive.tar | less
[root]# less archive.tarExtraire uniquement un fichier d’une archive .tar, tar.gz ou tar.bz2
Pour extraire un fichier spécifique d’une archive tar, spécifier le nom du fichier à la fin de la commande tar xvf.
[root]# tar xvf archive.tar /path/to/fileLa commande précédente permet de n’extraire que le fichier file de l’archive archive.tar.
[root]# tar xvfz archive.tar.gz /path/to/file
[root]# tar xvfj archive.tar.bz2 /path/to/fileExtraire uniquement un dossier d’une archive tar, tar.gz, tar.bz2
Pour n’extraire qu’un seul répertoire (ses sous-répertoires et fichiers inclus) d’une archive, spécifier le nom du répertoire à la fin de la commande tar xvf.
[root] tar xvf archive.tar /path/to/dir/Pour extraire plusieurs répertoires, spécifier chacun des noms les uns à la suite des autres :
[root] tar xvf archive_file.tar /path/to/dir1/ /path/to/dir2/
[root] tar xvfz archive_file.tar.gz /path/to/dir1/ /path/to/dir2/
[root] tar xvfj archive_file.tar.bz2 /path/to/dir1/ /path/to/dir2/Extraire un groupe de fichiers d’une archive tar, tar.gz, tar.bz2 grâce à des expressions régulières (regex)
Spécifier une regex pour extraire les fichiers correspondants au pattern spécifié.
Par exemple, pour extraire tous les fichiers avec l’extension .conf :
[root] tar xvf archive_file.tar --wildcards '*.conf'Clefs :
-
--wildcards *.conf correspond aux fichiers avec l’extension .conf.
Ajouter un fichier ou un répertoire à une archive existante
Il est possible d’ajouter des fichiers à une archive existante avec la clef r.
Par exemple, pour ajouter un fichier :
[root]# tar rvf archive.tar filetoaddLe fichier filetoadd sera ajouté à l’archive tar existante. Ajouter un répertoire est similaire :
[root]# tar rvf archive_name.tar dirtoadd|
Il n’est pas possible d’ajouter des fichiers ou des dossiers à une archive compressée. |
Vérifier l’intégrité d’une archive
L’intégrité d’une archive peut être testée avec la clef W au moment de sa création :
[root]# tar cvfW file_name.tar dir/La clef W permet également de comparer le contenu d’une archive par rapport au système de fichiers :
[root]# tar tvfW file_name.tar
Verify 1/file1
1/file1: Mod time differs
1/file1: Size differs
Verify 1/file2
Verify 1/file3La vérification avec la clef W ne peut pas être effectuée avec une archive compressée. Il faut utiliser la clef d :
[root]# tar dfz file_name.tgz
[root]# tar dfj file_name.tar.bz2Estimer la taille d’une archive
La commande suivante estime la taille d’un fichier tar en KB avant de la créer :
[root]# tar cf - /directory/to/archive/ | wc -c
20480
[root]# tar czf - /directory/to/archive/ | wc -c
508
[root]# tar cjf - /directory/to/archive/ | wc -c
428Ajout d’éléments à une sauvegarde existante
tar {r|A}[clé(s)] [support] [fichiers(s)]Exemple :
[root]# tar rvf /sauvegardes/home.133.tar /etc/passwd| Clef | Description |
|---|---|
r |
Ajoute un ou plusieurs fichiers à la fin d’une sauvegarde sur support à accès direct (disque dur). |
A |
Ajoute un ou plusieurs fichiers à la fin d’une sauvegarde sur support à accès séquentiel (bande). |
|
Si la sauvegarde a été réalisée en mode relatif, ajoutez des fichiers en mode relatif. Si la sauvegarde a été réalisée en mode absolu, ajoutez des fichiers en mode absolu. En mélangeant les modes, vous risquez d’avoir des soucis au moment de la restauration. |
Lire le contenu d’une sauvegarde
tar t[clé(s)] [support]Exemple :
[root]# tar tvf /sauvegardes/home.133.tar
[root]# tar tvfj /sauvegardes/home.133.tar.bz2| Clef | Description |
|---|---|
t |
Affiche le contenu d’une sauvegarde (compressée ou non). |
|
Toujours vérifier le contenu d’une sauvegarde. |
| Clés | Fichiers | Suffixe |
|---|---|---|
cvf |
home |
home.tar |
cvfP |
/etc |
etc.P.tar |
cvfz |
usr |
usr.tar.gz |
cvfj |
usr |
usr.tar.bz2 |
cvfPz |
/home |
home.P.tar.gz |
cvfPj |
/home |
home.P.tar.bz2 |
CoPy Input Output - cpio
La commande cpio permet la sauvegarde sur plusieurs supports successifs sans indiquer d’options.
Il est possible d’extraire tout ou partie d’une sauvegarde.
|
cpio ne permet pas de sauvegarder directement une arborescence. L’arborescence ou fichiers sont donc transmis sous forme de liste à cpio. |
Il n’y a aucune option, comme pour la commande tar, permettant de sauvegarder et de compresser en même temps. Cela s’effectue donc en deux temps : la sauvegarde puis la compression.
Pour effectuer une sauvegarde avec cpio, il faut préciser une liste des fichiers à sauvegarder.
Cette liste est fourni avec les commandes find, ls ou cat.
-
find : parcourt une arborescence, récursif ou non ;
-
ls : liste un répertoire, récursif ou non ;
-
cat : lit un fichier contenant les arborescences ou fichiers à sauvegarder.
|
ls ne peut pas être utilisé avec -l (détails) ou -R (récursif). Il faut une liste simple de noms. |
Créer une sauvegarde
[cde de fichiers |] cpio {-o| --create} [-options] [<fic-liste] [>support]Exemple :
[root]# find /etc | cpio -ov > /sauvegardes/etc.cpioLe résultat de la commande find est envoyé en entrée de la commande cpio par l’intermédiaire du signe “|” (AltGr+6). Ici, la commande find /etc renvoie une liste de fichiers correspondant au contenu du répertoire /etc (en récursif) à la commande cpio qui en effectue la sauvegarde. Ne surtout pas oublier le signe > lors de la sauvegarde.
| Options | Description |
|---|---|
-o |
Crée une sauvegarde (output). |
-v |
Affiche le nom des fichiers traités. |
-F |
Désigne la sauvegarde à modifier (support). |
Sauvegarde vers un support :
[root]# find /etc | cpio -ov > /dev/rmt0Le support peut être de plusieurs types :
-
/dev/rmt0 : lecteur de bande ;
-
/dev/sda5 : une partition.
Type de sauvegarde
-
Sauvegarde avec chemin relatif
[root]# cd /
[root]# find etc | cpio -o > /sauvegardes/etc.cpio-
Sauvegarde avec chemin absolu
[root]# find /etc | cpio -o > /sauvegardes/etc.A.cpio|
Si le chemin indiqué au niveau de la commande “find” est en absolu alors la sauvegarde sera réalisée en absolu. Si le chemin indiqué au niveau de la commande “find” est en relatif alors la sauvegarde sera réalisée en relatif. |
Ajouter à une sauvegarde
[cde de fichiers |] cpio {-o| --create} -A [-options] [<fic-liste] {F|>support}Exemple :
[root]# find /etc/shadow | cpio -o -AF FicSyst.A.cpioL’ajout de fichiers n’est possible que sur un support à accès direct.
| Option | Description |
|---|---|
-A |
Ajoute un ou plusieurs fichiers à une sauvegarde sur disque. |
-F |
Désigne la sauvegarde à modifier. |
Compresser une sauvegarde
-
Sauvegarder puis compresser
[root]# find /etc | cpio –o > etc.A.cpio
[root]# gzip /sauvegardes/etc.A.cpio
[root]# ls /sauvegardes/etc.A.cpio*
/sauvegardes/etc.A.cpio.gz-
Sauvegarder et compresser
[root]# find /etc | cpio –o | gzip > /sauvegardes/etc.A.cpio.gzIl n’y a aucune option, comme pour la commande tar, permettant de sauvegarder et de compresser en même temps. Cela s’effectue donc en deux temps : la sauvegarde puis la compression.
La syntaxe de la première méthode est plus facile à comprendre et à retenir, car elle s’effectue en deux temps.
Pour la première méthode, le fichier de sauvegarde est automatiquement renommé par l’utilitaire gzip qui rajoute .gz à la fin du nom de ce fichier. De même l’utilitaire bzip2 rajoute automatiquement .bz2.
Lire le contenu d’une sauvegarde
cpio -t [-options] [<fic-liste]Exemple :
[root]# cpio -tv </sauvegardes/etc.152.cpio | less| Options | Description |
|---|---|
-t |
Lit une sauvegarde. |
-v |
Affiche les attributs des fichiers. |
Après avoir réalisé une sauvegarde, il faut lire son contenu pour être certain qu’il n’y a pas eu d’erreur.
De la même façon, avant d’effectuer une restauration, il faut lire le contenu de la sauvegarde qui va être utilisée.
Restaurer une sauvegarde
cpio {-i| --extract} [-E fichier] [-options] [<support]Exemple :
[root]#cpio -iv </sauvegardes/etc.152.cpio | less| Options | Description |
|---|---|
-i |
Restauration complète d’une sauvegarde . |
-E fichier |
Restaure uniquement les fichiers dont le nom est contenu dans fichier. |
-d |
Reconstruit l’arborescence manquante. |
-u |
Remplace tous les fichiers même s’ils existent. |
--no-absolute-filenames |
Permet de restaurer une archive effectuée en mode absolu de manière relative. |
|
Par défaut, au moment de la restauration, les fichiers sur le disque dont la date de dernière modification est plus récente ou égale à la date de la sauvegarde ne sont pas restaurés (afin d’éviter d’écraser des informations récentes par des informations plus anciennes). L’option -u permet au contraire de restaurer d’anciennes versions des fichiers. |
Exemples :
-
Restauration en absolu d’une sauvegarde absolue :
[root]# cpio –iv <home.A.cpio-
Restauration en absolu sur une arborescence existante :
[root]# cpio –iuv <home.A.cpioL’option “u” permet d’écraser des fichiers existants à l’endroit où s’effectue la restauration. * Restauration en relatif d’une sauvegarde absolue :
[root]# cpio –iv --no-absolute-filenames <home.A.cpioL’option longue “--no-absolute-filenames” permet une restauration en mode relatif. En effet le “/” en début de chemin est enlevé.
-
Restauration en relatif d’une sauvegarde relative :
[root]# cpio –iv <etc.cpio-
Restauration en absolu du fichier « passwd » :
echo "/etc/passwd" > tmp;cpio –iuE tmp <etc.A.cpio; rm -f tmpUtilitaires de compression - décompression
Le fait d’utiliser la compression au moment d’une sauvegarde peut présenter un certain nombre d’inconvénients :
-
Allonge le temps de la sauvegarde ainsi que celui de la restauration.
-
Rend impossible l’ajout de fichiers à cette sauvegarde.
|
Il vaut donc mieux effectuer une sauvegarde et la compresser qu’effectuer la compression lors de la sauvegarde. |
Compresser avec gzip
La commande gzip compresse les données.
gzip [options] [fichier ...]Exemple :
[root]# gzip usr.tar
[root]# ls
usr.tar.gzLe fichier reçoit l’extension .gz.
Il conserve les mêmes droits et les mêmes dates de dernier accès et de modification.
Compresser avec bunzip2
La commande bunzip2 compresse également les données.
bzip2 [options] [fichier ...]Exemple :
[root]# bzip2 usr.cpio
[root]# ls
usr.cpio.bz2Le nom du fichier reçoit l’extension .bz2.
La compression par “bzip2” est meilleure que celle par “gzip” mais dure plus longtemps.
Décompresser avec gunzip
La commande gunzip décompresse les données compressées.
gunzip [options] [fichier ...]Exemple :
[root]# gunzip usr.tar.gz
[root]# ls
usr.tarLe nom du fichier est tronqué par gunzip et se voit enlever l’extension .gz .
Gunzip décompresse également les fichiers portant les extensions suivantes :
-
.z ;
-
-z ;
-
_z.
Décompresser avec bunzip2
La commande bunzip2 décompresse les données compressées.
bzip2 [options] [fichier ...]Exemple :
[root]# bunzip2 usr.cpio.bz2
[root]# ls
usr.cpioLe nom du fichier est tronqué par bunzip2 et se voit enlever l’extension .bz2 .
bunzip2 décompresse également le fichier portant les extensions suivantes :
-
-bz ;
-
.tbz2 ;
-
tbz.
Démarrage du système
Démarrage de l’ordinateur
Séquence de démarrage
La séquence de démarrage du système est variable en fonction du système mais peut d’une manière générale être découpée selon les étapes définies ci-dessous.
-
démarrage de l’ordinateur ou amorçage ;
-
exécution du chargeur de démarrage ;
-
démarrage du noyau ;
-
lancement du processus init ;
-
lancement des scripts de démarrage.
Amorçage matériel
Après la mise sous tension, un programme stocké en mémoire morte sur la carte mère prend le contrôle. Sur les PC, ce programme est appelé le BIOS ou UEFI pour les dernières générations de carte mère. Pour la suite du cours nous ne verrons que le BIOS.
-
BIOS : Basic Input Output System ;
-
UEFI : Unified Extensible Firmware Interface ;
-
POST : Power On Self Test.
Séquence d’amorçage matériel :
-
mise sous tension de l’ordinateur ;
-
lecture BIOS/UEFI stocké en mémoire morte ;
-
BIOS effectue un autotest : POST ;
-
lecture des paramètres (périphériques de boot, …) ;
-
lancement du chargeur de démarrage trouvé.
Le chargeur de démarrage
Le chargeur de démarrage localise le noyau du système d’exploitation sur le disque, le charge et l'exécute.
La majorité des chargeurs sont interactifs, ils permettent :
-
de spécifier un noyau ;
-
de positionner des paramètres optionnels.
|
Spécification d’un noyau alternatif : un noyau de sauvegarde dans le cas où la dernière version compilée ne fonctionne pas. |
Types de chargeurs
On peut retrouver généralement sous Linux :
-
Grub : GRand Unified Bootloader (le plus répandu) ;
-
Lilo : LInux LOader (délaissé par les développeurs) ;
-
Elilo : pour UEFI.
|
Pour la suite du cours nous utiliserons GRUB. |
Le chargeur GRUB
Le chargeur GRUB est un programme de multiboot permettant de choisir entre plusieurs systèmes d’exploitation lors du démarrage.
La technique du chain-loading lui permet de démarrer une grande variété de systèmes d’exploitation. Il peut donc aussi bien charger des systèmes compatibles avec le multiboot que des systèmes non compatibles.
La configuration du GRUB est lue au démarrage du système.
|
Le Chain-loading est une technique qui permet à un chargeur de lancer un autre chargeur en l’encapsulant. |
GRUB reconnaît nativement divers systèmes de fichiers.
Il fournit un interpréteur de commandes permettant le chargement manuel d’un système d’exploitation et le changement de la configuration au boot.
GRUB permet d’agir en interactif sur le démarrage.
GRUB peut être utilisé avec différentes interfaces. Beaucoup de distributions GNU/Linux utilisent le support graphique de GRUB pour afficher au démarrage de l’ordinateur un menu avec une image de fond et parfois un support de la souris.
GRUB peut télécharger des images de systèmes d’exploitations depuis un réseau et supporte donc les ordinateurs sans disques. Il peut donc décompresser ces images pour les charger ensuite.
Choix du système
GRUB fournit une interface avec menu à partir de laquelle vous pouvez choisir un système d’exploitation qui sera ensuite amorcé.
Ce menu est basé sur le fichier de configuration grub.conf qui se trouve dans le répertoire /boot/grub/.
En fonction des distributions, /etc/grub.conf peut être un lien symbolique vers ce fichier.
|
Lors des sélections dans le GRUB, le clavier est en qwerty. |
| Touche | Action |
|---|---|
[ENTREE] |
Démarre le système sélectionné. |
[e] |
Édite la configuration du système. |
[a] |
Permet de modifier les arguments. |
[c] |
Permet d’utiliser l’interface Shell de GRUB. |
La touche [ENTREE] permet de lancer l’initialisation du serveur.
Une fois le démarrage terminé, le système affiche les messages placés dans le fichier /etc/issue et propose de saisir un login puis un mot de passe pour se connecter.
La touche [e] permet d’éditer la configuration avant de démarrer. Il est alors possible de modifier les lignes en les éditant une à une avec la touche [e].
Après avoir édité la ligne sélectionnée, procéder à la modification puis valider la ligne modifiée en utilisant la touche [ENTREE].
Pour initialiser le système en tenant compte de ces modifications, utiliser la touche [b] (comme 'boot‘).
La touche [a] / [q] permet de modifier les arguments du noyau.
La touche [c] permet d' obtenir l’interface Shell de Grub.
Fichier /boot/grub/grub.conf
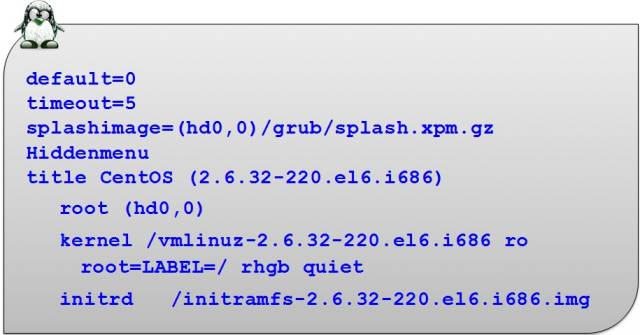
La première partie est constituée de lignes de commentaires décrivant la structure du fichier.
Aucune compilation de ce fichier de configuration ne sera nécessaire.
Explications des options :
| Variable | Observation |
|---|---|
default=0 |
Correspond au système d’exploitation lancé par défaut. La première rubrique title porte le numéro 0. |
timeout=5 |
GRUB amorcera automatiquement le système par défaut au bout de 5 secondes, à moins d’être interrompu. |
splashimage |
Déclaration de l’image qui s’affiche avec le chargeur Grub. Il faut indiquer l’emplacement de cette image. Les systèmes de fichiers n’étant pas encore montés, indiquer le disque et la partition de /boot (hd0,0), le chemin jusqu’à l’image grub/ et enfin le nom de votre image splash.xpm.gz. |
hiddenmenu |
Sert à masquer le menu Grub et après le délai du timeout, le système se lancera automatiquement en fonction de l’option default. |
title |
Il s’agit en fait du nom qui apparaîtra dans le menu Grub (exemple “ma distrib Linux préférée”). En règle général, le nom du système est choisi : exemple Fedora, Suse, Ubuntu, Vista, Xp, Frugal, etc,… et éventuellement la version du noyau. Un seul nom par rubrique title, il faut donc déclarer autant de lignes 'title' qu’il y a d’options de démarrage ou de systèmes installés. |
root |
Indique le disque puis la partition (hdx,y) où se trouvent les fichiers permettant l’initialisation du système (exemple : (hd0,0), correspondant à la partition /boot) pour ce "title". |
kernel |
Indique le nom du noyau à charger, son emplacement et les options utiles à son démarrage pour ce "title". |
initrd |
initrd (INITial RamDisk) charge un ramdisk initial pour une image de démarrage au format Linux et définit les paramètres adéquats dans la zone de configuration de Linux en mémoire pour ce "title". |
Sécuriser GRUB
GRUB est par défaut très permissif. Certaines opérations interactives ne nécessitent pas d’authentification. Ainsi, il est possible d’exécuter des commandes root sans s’être authentifié !
|
L’accès au menu interactif doit être protégé. |
Définir un mot de passe
Il faut définir un mot de passe avec la directive password dans le fichier /boot/grub/grub.conf.
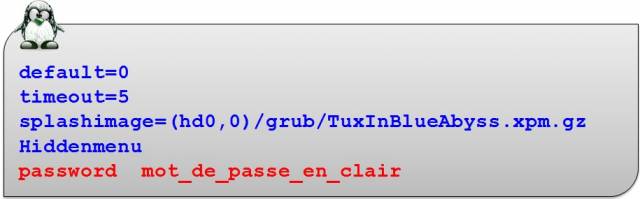
La directive password est ajoutée dans la partie globale avant la directive title .
Quand la directive password est saisie dans /boot/grub/grub.conf, GRUB interdit tout contrôle interactif, jusqu’à ce que la touche [p] soit pressée et qu’un mot de passe correct soit entré.
Chiffrer le mot de passe
Le mot de passe peut être chiffré.
À l’aide d’un shell traditionnel :
[root]# grub-crypt >> /boot/grub/grub.conf
Dans le fichier grub.conf l’option [--encrypted] devra être ajoutée entre la directive password et le mot de passe chiffré.
Vous pouvez chiffrer votre mot de passe avec la commande grub-crypt.
Copiez le mot de passe chiffré dans votre fichier de configuration et indiquez dans la rubrique qu’il est chiffré.
[root]# grub-crypt
Password : mdpauser1
Retype password : mdpauser1
$6$uK6Bc/$90LR/0QW.14G4473EaENd|
Le hash du mot de passe fourni par la commande grub-crypt commence par un $6$ car l’algorithme utilisé est le SHA-512.
|
Dans le but de récupérer ce mot de passe et de l’insérer directement dans le fichier grub.conf, utilisez la commande suivante :
[root]# grub-crypt >>/boot/grub/grub.conf
Menu interactif verrouillé
Pour agir sur l’interactivité du démarrage, utiliser la touche [p] pour saisir le mot de passe et ensuite disposer des options permettant d’agir sur le lancement du noyau.
Lancement verrouillé
Le lancement d’un système peut être verrouillé avec la directive lock positionnée en dessous de la ligne title à verrouiller.
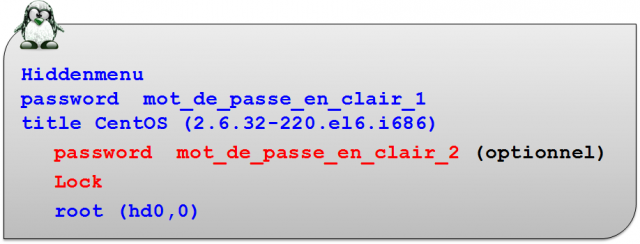
-
Le mot de passe sera systématiquement demandé.
-
Pourquoi verrouiller le lancement d’un système ? L’administrateur peut prévoir une rubrique qui lancera son système en mode single. Aucun utilisateur ne devra donc utiliser cette rubrique.
-
Il est possible d’affecter un mot de passe différent pour chaque menu. Pour cela il suffira de remettre une directive password avec un nouveau mot de passe dans chaque rubrique title.
Démarrage du noyau
Au démarrage du système, GRUB apparaît.
[ENTREE] active la configuration par défaut.
Une autre touche fait apparaître le menu du GRUB.
Niveaux de démarrage
s ou single |
Le processus init démarre le système en mode mono-utilisateur. Par défaut l’utilisateur est connecté en tant que root sans fournir de mot de passe. |
1 - 5 |
Le processus init démarre le système avec le niveau demandé. |
Étapes du démarrage
Principales étapes du démarrage :
-
chargement du noyau (processus 0) ;
-
installation des périphériques via leur pilote ;
-
démarrage du gestionnaire de swap ;
-
montage du système de fichiers racine ;
-
création par le noyau du premier processus qui porte le numéro 1 ;
-
ce processus exécute le programme /sbin/init en lui passant les paramètres qui ne sont pas déjà gérés par le noyau.
Le processus init (généralités)
Les différents niveaux d’exécution
0 |
Arrête le système. |
1 |
Mode mono-utilisateur (console). |
2 |
Mode multi-utilisateurs. Les systèmes de fichiers sont montés. Le service réseau est démarré. |
3 |
Sur-ensemble du niveau 2. Il est associé au démarrage des services de partage à distance. |
4 |
Mode multi-utilisateurs spécifique au site informatique. |
5 |
Sur-ensemble du niveau 3. Interface X-Window (graphique). |
6 |
Redémarre le système. |
s, S, single |
Mode mono-utilisateur (single). Les systèmes de fichiers sont montés. Seuls les processus fondamentaux pour le bon fonctionnement du système sont activés. Un shell en mode root est activé sur une console. Le répertoire /etc n’est pas indispensable. |
Il n’y a qu’un niveau d’exécution actif à la fois.
La commande init
La commande init permet de changer le niveau d’exécution courant .
init [-options] [0123456Ss]Exemple :
[root]# init 5
La commande runlevel
La commande runlevel permet de connaître le niveau d’exécution courant.
runlevelExemple :
[root]# runlevel
N 3Dans cet exemple, le système se trouve au niveau d’exécution 3 - Multiuser.
Le N indique que le niveau d’exécution précédent était le démarrage du système. Après un init 5, le résultat de la commande serait alors :
[root]# runlevel
3 5Il n’y a qu’un niveau d’exécution actif à la fois.
Le fichier /etc/inittab
Lors du démarrage, à la création du processus init, le niveau est celui défini dans GRUB ou sinon celui dans /etc/inittab.
Le niveau défini dans GRUB est prioritaire à celui défini dans inittab.
# For information on how to write upstart event handlers, or how
# upstart works, see init(5), init(8), and initctl(8).
# Default runlevel. The runlevels used are:
# 0 - halt (Do NOT set initdefault to this)
# 1 - Single user mode
# 2 - Multiuser, without NFS (The same as 3, if you do not have networking)
# 3 - Full multiuser mode
# 4 – unused
# 5 - X11
# 6 - reboot (Do NOT set initdefault to this)
id:5:initdefault:Changement de niveau
Lorsqu’un changement de niveau est effectué, le processus init envoie un signal SIGTERM (15) à tous les processus non concernés par le nouveau niveau.
Un délai de 5 secondes est accordé afin que les processus se terminent correctement. Après ce délai, le processus init envoie un deuxième signal SIGKILL (9) à tous les processus non terminés.
init démarre ensuite les processus concernés par le nouveau niveau d’exécution.
Activer ou désactiver les terminaux
Pour activer ou désactiver les terminaux, il faut modifier la variable ACTIVE_CONSOLES dans le fichier /etc/sysconfig/init.
Exemples :
ACTIVE_CONSOLES="/dev/tty[1-6]" #Active les terminaux de 1 à 6
ACTIVE_CONSOLES="/dev/tty[1-6] /dev/tty8 /dev/tty9" #Active les terminaux de 1 à 6, le 8 et le 9Ne pas oublier les “ “.
Le système doit être redémarré pour la prise en compte.
|
Au niveau de démarrage 5, le système ne prend pas en compte le fichier /etc/sysconfig/init. En cas d’erreur de manipulation dans ce fichier, un moyen de redémarrer un serveur est de force le redémarrage en init 5 ! |
Autoriser à root l’accès aux terminaux
Par défaut, une console déclarée dans /etc/sysconfig/init n’est accessible que par les utilisateurs.
Il faut renseigner le fichier /etc/securetty en ajoutant le nom de ce nouveau terminal pour autoriser root à s’y connecter.
Exemple suivant, à la dernière ligne (tty6) le # est retiré permettant l’accès à root sur ce terminal.
console
#vc/1
#vc/2
#vc/3
#vc/4
#vc/5
#vc/6
#tty1
#tty2
#tty3
#tty4
#tty5
tty6Le processus init (démon)
Démarrage des démons
init lance le script /etc/rc.d/rc.sysinit quelque soit le niveau.
Init exécute ensuite le script /etc/rc.d/rc en lui passant en paramètre le niveau d’exécution demandé
Script de démarrage des services
Pour chaque service, il y a un script de démarrage stocké dans /etc/rc.d/init.d.
Chaque script accepte au minimum en argument :
-
stop : pour arrêter le service ;
-
start : pour démarrer le service ;
-
restart : pour redémarrer le service ;
-
status : pour connaître l’état du service.
Répertoires d’ordonnancement
Pour chaque niveau d’exécution, il existe un répertoire correspondant : /etc/rc.d/rc[0-6].d/.
Ces répertoires contiennent les liens symboliques vers les scripts placés dans /etc/rc.d/init.d.
L’avantage du lien : il n’existe qu’un seul exemplaire du script du service.
Nom des liens
Mise en route (Start) : SXXnom
Arrêt (Kill) : KYYnom
XX et YY : nombre de 00 à 99 qui guide l’ordre d’exécution (Start ou Kill).
nom : nom exact du service à démarrer ou à arrêter tel qu’écrit dans /etc/rc.d/init.d/.
La somme des nombres est un complément à 100 : XX + YY = 100.
Cette méthode permet d’ordonnancer le démarrage et l’arrêt des services. Un service qui est démarré en premier doit être le dernier à s’arrêter. La liste étant lue dans l’ordre alphabétique.
Exemple :
Dans /etc/rc.d/rc3.d/, nous avons :
-
K15httpd
-
S10network
-
S26acpid
Donc, pour le niveau d’exécution 3 (rc3.d) :
-
le service httpd doit être arrêté (lettre K),
-
les services network et acpid doivent être lancés (lettre S) dans cet ordre (numéro du service network 10 plus petit que celui de acpid 26)
Le programme /etc/rc.d/rc
Ce programme est lancé par init avec le niveau d’exécution en paramètre.
Il comporte deux boucles.
Init lance le script rc avec le niveau X en paramètre.
Première boucle : lecture des scripts d’arrêt K… présents dans rcX.d.
Deuxième boucle : lecture des scripts de démarrage S… présents dans rcX.d.
Architecture de démarrage
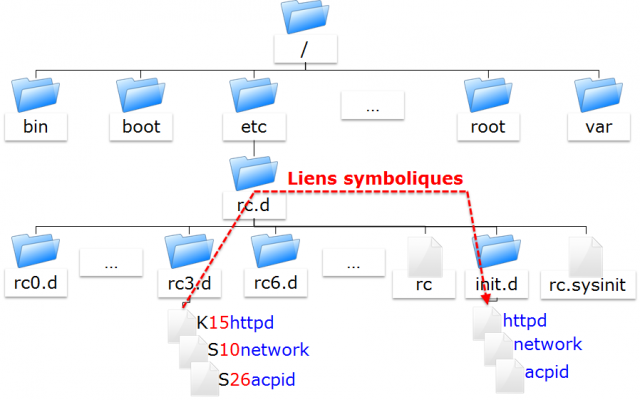
La gestion des services
Comme il n’existe qu’un seul exemplaire du fichier script par service sous /etc/rc.d/init.d, leur gestion est facilitée. La gestion des liens s’effectue soit :
-
manuellement avec la commande ln ;
-
avec la commande de gestion des services chkconfig.
La commande ln
Créer un lien symbolique manuellement.
ln -s source destinationExemple :
[root]# cd /etc/rc.d/rc2.d
[root]# ln –s ../init.d/numlock S85numlockIl faut alors créer tous les liens (K ou S) pour chaque niveau de démarrage.
La commande chkconfig
La commande chkconfig permet de gérer un service.
Il faut les deux lignes suivantes au début de chaque script.
# chkconfig: [niveau_exécution] [num_start] [num_kill]
# description: [descriptif du script]Exemple 1 :
# chkconfig: 2345 10 90
# description: Commentaires libresExemple 2 :
# chkconfig: -
# description: Commentaires libresLe - après chkconfig: signifie que le service ne doit jamais être démarré.
Gérer et visualiser l’état d’un service
chkconfig [--options] [service]
chkconfig --level service on|off|resetExemple :
[root]# chkconfig --list network
network 0:arrêt 1:arrêt 2:arrêt 3:arrêt 4:arrêt 5:arrêt 6:arrêt| Option longue | Description |
|---|---|
--list |
Visualise l’état des services (--list seul liste tous les services créés). |
--add |
Crée des liens symboliques. |
--del |
Supprime des liens symboliques. |
--level |
Modifie les liens symboliques. |
La commande chkconfig --list lit les niveaux définis dans l’en-tête du service et affiche la configuration de démarrage du service.
Cette commande ne donne pas un état actuel du service.
Arrêt ne signifie pas que le service est arrêté, mais qu’il ne sera pas démarré au niveau spécifié.
Un autre moyen de visualiser les liens symboliques en une seule commande :
[root]# ls -l /etc/rc.d/rc*.d/*
Créer les liens symboliques
chkconfig --add service
Exemple :
[root]# chkconfig --add network
[root]# chkconfig --list network
network 0:arrêt 1:arrêt 2:marche 3:marche 4:marche 5:marche 6:arrêtchkconfig --add lit les niveaux définis dans l’en-tête du service et crée les liens correspondants.
Exemple :
# chkconfig: 235 90 10chkconfig crée les liens S90… dans les répertoires définis /etc/rc.d/rc2.d, rc3.d et rc5.d et les liens K10… dans les répertoires restants /etc/rc.d/rc0.d, rc1.d, rc4.d et rc6.d
Afin d’éviter les incohérences, faire un chkconfig --del nomduservice avant le chkconfig --add.
Supprimer des liens symboliques
chkconfig --del nomduservice
Exemple :
[root]# chkconfig --del network
[root]# chkconfig --list network
network 0:arrêt 1:arrêt 2:arrêt 3:arrêt 4:arrêt 5:arrêt 6:arrêtModifier des liens symboliques
chkconfig [--level niveaux] service <on | off>
Exemple :
[root]# chkconfig –-level 235 atd on
[root]# chkconfig –-level 0146 atd off--level |
Spécification du niveau auquel est créé le lien symbolique. |
on |
Le lien permettant de lancer le service est créé (Sxx…). |
off |
Le lien permettant d’arrêter le service est créé (Kxx…). |
Démarrage d’un service
Manuellement :
-
Avec un script de lancement :
/chemin/script [status|start|stop|restart]
Exemple :
[root]#/etc/rc.d/init.d/crond start
Démarrage de crond : [ OK ]
[root]#/etc/rc.d/init.d/crond status
crond (pid 4731) en cours d'exécution-
Avec la commande service :
service script [status|start|stop|restart]
Exemple :
[root]# service crond start
Démarrage de crond : [ OK ]
[root]# service crond status
crond (pid 4731) en cours d'exécutionLa commande service prend en compte tous les scripts placés dans /etc/rc.d/init.d.
|
La commande service n’existe que dans le monde des distributions RHEL ! |
Arrêt du système
Les opérations de maintenance, diagnostics, modifications de logiciels, ajouts et retraits de matériel, taches administratives, coupures électriques, … nécessitent parfois l’arrêt du système.
Cet arrêt peut être planifié, périodique ou impromptu et demander une réactivité immédiate.
Tous les systèmes Unix, y compris ceux fonctionnant sur PC doivent être mis hors service en utilisant les commandes décrites dans cette section.
Ceci garantit l’intégrité du disque et la terminaison propre des différents services du système.
Arrêt programmé du système :
-
utilisateurs prévenus de l’arrêt ;
-
applications arrêtées proprement ;
-
intégrité des systèmes de fichiers assurée ;
-
sessions utilisateurs stoppées.
En fonction des options, le système :
-
passe en mode mono-utilisateur ;
-
est arrêté ;
-
est redémarré.
Commandes de mise hors service :
-
init ;
-
shutdown ;
-
halt ;
-
reboot.
Commande shutdown
La commande shutdown éteint le système.
shutdown [-t sec] [options] heure [message-avertissement]
Exemples :
[root]# shutdown –r +2 "arrêt puis reboot dans 2 minutes"
[root]# shutdown –r 10:30 "arrêt puis reboot à 10h30"
[root]# shutdown –h now "arrêt électrique"Options |
Commentaires |
-t sec |
Attendre sec entre le message d’avertissement et le signal de fin aux processus |
-r |
Redémarrer la machine après l’arrêt du système |
-h |
Arrêter la machine après l’arrêt du système |
-P |
Éteindre l’alimentation |
-f |
Ne pas effectuer de fsck en cas de redémarrage |
-F |
Forcer l’utilisation de fsck en cas de redémarrage |
-c |
Annuler un redémarrage en cours |
heure : Quand effectuer le shutdown (soit une heure fixe hh:mm, soit un délai d’attente en minute +mm).
message-avertissement : Message à envoyer à tous les utilisateurs.
Commande halt
La commande halt provoque un arrêt immédiat du système.
[root]# halt
Cette commande appelle le processus init
halt ⇒ init 0
Commande reboot
La commande reboot provoque un redémarrage immédiat du système.
[root]# reboot
Cette commande appelle le processus init
reboot ⇒ init 6
Démarrage du système sous CentOS 7
Le processus de démarrage
Il est important de comprendre le processus de démarrage de Linux pour pouvoir résoudre les problèmes qui peuvent y survenir.
Le processus de démarrage comprend :
Le démarrage du BIOS
Le BIOS (Basic Input/Output System) effectue le test POST (power on self test) pour détecter, tester et initialiser les composants matériels du système.
Il charge ensuite le MBR (Master Boot Record).
Le Master boot record (MBR)
Le Master Boot Record correspond aux 512 premiers bytes du disque de démarrage. Le MBR découvre le périphérique de démarrage et charge le chargeur de démarrage GRUB2 en mémoire et lui transfert le contrôle.
Les 64 bytes suivants contiennent la table de partition du disque.
Le chargeur de démarrage GRUB2 (Bootloader)
Le chargeur de démarrage par défaut de la distribution CentOS 7 est GRUB2 (GRand Unified Bootloader). GRUB2 remplace l’ancien chargeur de démarrage Grub (appelé également GRUB legacy).
Le fichier de configuration de GRUB 2 se situe sous /boot/grub2/grub.cfg mais ce fichier ne doit pas être directement édité.
Les paramètres de configuration du menu de GRUB2 se trouvent sous /etc/default/grub et servent à la génération du fichier grub.cfg.
# cat /etc/default/grub
GRUB_TIMEOUT=5
GRUB_DEFAULT=saved
GRUB_DISABLE_SUBMENU=true
GRUB_TERMINAL_OUTPUT="console"
GRUB_CMDLINE_LINUX="rd.lvm.lv=rhel/swap crashkernel=auto rd.lvm.lv=rhel/root rhgb quiet net.ifnames=0"
GRUB_DISABLE_RECOVERY="true"Si des changements sont effectués à un ou plusieurs de ces paramètres, il faut lancer la commande grub2-mkconfig pour régénérer le fichier /boot/grub2/grub.cfg.
[root] # grub2-mkconfig –o /boot/grub2/grub.cfg-
GRUB2 cherche l’image du noyau compressé (le fichier vmlinuz) dans le répertoire /boot.
-
GRUB2 charge l’image du noyau en mémoire et extrait le contenu du fichier image initramfs dans un dossier temporaire en mémoire en utilisant le système de fichier tmpfs.
Le noyau
Le noyau démarre le processus systemd avec le PID 1.
root 1 0 0 02:10 ? 00:00:02 /usr/lib/systemd/systemd --switched-root --system --deserialize 23systemd
Systemd est le père de tous les processus du système. Il lit la cible du lien /etc/systemd/system/default.target (par exemple /usr/lib/systemd/system/multi-user.target) pour déterminer la cible par défaut du système. Le fichier défini les services à démarrer.
Systemd positionne ensuite le système dans l’état défini par la cible en effectuant les tâches d’initialisations suivantes :
-
Paramétrer le nom de machine
-
Initialiser le réseau
-
Initialiser SELinux
-
Afficher la bannière de bienvenue
-
Initialiser le matériel en se basant sur les arguments fournis au kernel lors du démarrage
-
Monter les systèmes de fichiers, en incluant les systèmes de fichiers virtuels comme /proc
-
Nettoyer les répertoires dans /var
-
Démarrer la mémoire virtuelle (swap)
Protéger le chargeur de démarrage GRUB2
Pourquoi protéger le chargeur de démarrage avec un mot de passe ?
-
Prévenir les accès au mode utilisateur Single – Si un attaquant peut démarrer en mode single user, il devient l’utilisateur root.
-
Prévenir les accès à la console GRUB – Si un attaquant parvient à utiliser la console GRUB, il peut changer sa configuration ou collecter des informations sur le système en utilisant la commande cat.
-
Prévenir les accès à des systèmes d’exploitation non sécurisés. S’il y a un double boot sur le système, un attaquant peut sélectionner au démarrage un système d’exploitation comme DOS qui ignore les contrôles d’accès et les permissions des fichiers.
Pour protéger par mot de passe le GRUB2 :
-
Retirer –unrestricted depuis la déclaration principale CLASS= dans le fichier /etc/grub.d/10_linux.
-
Si un utilisateur n’a pas encore été configuré, utiliser la commande grub2-setpassword pour fournir un mot de passe à l’utilisateur root :
# grub2-setpasswordUn fichier /boot/grub2/user.cfg va être créé s’il n’était pas encore présent. Il contient le mot de passe hashé du GRUB.
|
Cet commande ne supporte que les configurations avec un seul utilisateur root. |
[root]# cat /boot/grub2/user.cfg
GRUB2_PASSWORD=grub.pbkdf2.sha512.10000.CC6F56....A21-
Recréer le fichier de configuration avec la commande grub2-mkconfig :
[root]# grub2-mkconfig -o /boot/grub2/grub.cfg
Generating grub configuration file ...
Found linux image: /boot/vmlinuz-3.10.0-327.el7.x86_64
Found initrd image: /boot/initramfs-3.10.0-327.el7.x86_64.img
Found linux image: /boot/vmlinuz-0-rescue-f9725b0c842348ce9e0bc81968cf7181
Found initrd image: /boot/initramfs-0-rescue-f9725b0c842348ce9e0bc81968cf7181.img
done-
Redémarrer le serveur et vérifier.
Toutes les entrées définies dans le menu du GRUB vont maintenant nécessiter la saisie d’un utilisateur et d’un mot de passe à chaque démarrage. Le système ne démarrera pas de noyau sans intervention directe de l’utilisateur depuis la console.
-
Lorsque l’utilisateur est demandé, saisir "root" ;
-
Lorsqu’un mot de passe est demandé, saisir le mot de passe fourni à la commande grub2-setpassword.
Pour ne protéger que l’édition des entrées du menu de GRUB et l’accès à la console, l’exécution de la commande grub2-setpassword est suffisante.
Systemd
Systemd est un gestionnaire de service pour les systèmes d’exploitation Linux.
Il est développé pour :
-
rester compatible avec les anciens scripts d’initialisation SysV,
-
fournir de nombreuses fonctionnalités comme le démarrage en parallèle des services systèmes au démarrage du système, l’activation à la demande de démons, le support des instantanés ou la gestion des dépendances entre les services.
|
Systemd est le système d’initialisation par défaut depuis la RedHat/CentOS 7. |
Systemd introduit le concept d’unités systemd.
| Type | Extension du fichier | Observation |
|---|---|---|
Unité de service |
.service |
Service système |
Unité cible |
.target |
Un groupe d’unités systemd |
Unité automount |
.automount |
Un point de montage automatique pour système de fichiers |
|
Il existe de nombreux types d’unités : Device unit, Mount unit, Path unit, Scope unit, Slice unit, Snapshot unit, Socket unit, Swap unit, Timer unit. |
-
Systemd supporte les instantanés de l’état du système et leur restauration.
-
Les points de montage peuvent être configurés comme des cibles systemd.
-
Au démarrage, systemd créé des sockets en écoute pour tous les services systèmes qui supportent ce type d’activation et passe ces sockets à ces services aussitôt qu’elles sont démarrées. Cela rend possible la relance d’un service sans perdre un seul message qui lui est envoyé par le réseau durant son indisponibilité. La socket correspondante reste accessible et tous les messages sont mis en file d’attente.
-
Les services systèmes qui utilisent D-BUS pour leurs communications inter-process peuvent être démarrés à la demande dès la première utilisation par un client.
-
Systemd stoppe ou relance uniquement les services en cours de fonctionnement. Les versions précédentes de CentOS tentaient directement de stopper les services sans vérifier leur état en cours.
-
Les services systèmes n’héritent d’aucun contexte (comme les variables d’environnements HOME et PATH). Chaque service fonctionne dans son propre contexte d’exécution.
Toutes les opérations des unités de service sont soumises à un timeout par défaut de 5 minutes pour empêcher un service mal-fonctionnant de geler le système.
Gérer les services systèmes
Les unités de service se terminent par l’extension de fichier .service et ont un but similaire à celui des scripts init. La commande systemctl est utilisée pour afficher, lancer, arrêter, redémarrer, activer ou désactiver des services système.
|
Les commandes service et chkconfig sont toujours disponibles dans le système et fonctionnent comme prévu, mais sont uniquement incluses pour des raisons de compatibilité et doivent être évitées. |
| service | systemctl | Description |
|---|---|---|
service name start |
systemctl start name.service |
Lancer un service |
service name stop |
systemctl stop name.service |
Stoppe un service |
service name restart |
systemctl restart name.service |
Relance un service |
service name reload |
systemctl reload name.service |
Recharge une configuration |
service name status |
systemctl status name.service |
Vérifie si un service fonctionne |
service name condrestart |
systemctl try-restart name.service |
Relance un service seulement s’il fonctionne |
service --status-all |
systemctl list-units --type service --all |
Affiche le status de tous les services |
| chkconfig | systemctl | Description |
|---|---|---|
chkconfig name on |
systemctl enable name.service |
Active un service |
chkconfig name off |
systemctl disable name.service |
Désactive un service |
chkconfig --list name |
systemctl status name.service |
Vérifie si un service fonctionne |
chkconfig --list |
systemctl list-unit-files --type service |
Liste tous les services et vérifie s’ils fonctionnent |
chkconfig --list |
systemctl list-dependencies --after |
Liste les services qui démarrent avant l’unité spécifiée |
chkconfig --list |
systemctl list-dependencies --before |
Liste les services qui démarrent après l’unité spécifiée |
Exemples :
systemctl stop nfs-server.service
# ou
systemctl stop nfs-serverPour lister toutes les unités chargées actuellement :
systemctl list-units --type servicePour lister toutes les unités pour vérifier si elles sont activées :
systemctl list-unit-files --type servicesystemctl enable httpd.service
systemctl disable bluetooth.serviceExemple de fichier .service pour le service postfix
postfix.service Unit File
What follows is the content of the /usr/lib/systemd/system/postfix.service unit file as currently provided by the postfix package:
[Unit]
Description=Postfix Mail Transport Agent
After=syslog.target network.target
Conflicts=sendmail.service exim.service
[Service]
Type=forking
PIDFile=/var/spool/postfix/pid/master.pid
EnvironmentFile=-/etc/sysconfig/network
ExecStartPre=-/usr/libexec/postfix/aliasesdb
ExecStartPre=-/usr/libexec/postfix/chroot-update
ExecStart=/usr/sbin/postfix start
ExecReload=/usr/sbin/postfix reload
ExecStop=/usr/sbin/postfix stop
[Install]
WantedBy=multi-user.targetUtiliser les targets systèmes
Sur CentOS7/RHEL7, le concept des niveaux d’exécution a été remplacé par les cibles Systemd.
Les cibles Systemd sont représentées par des unités de cible (target units). Les unités de cible se terminent par l’extension de fichier .target et leur unique but consiste à regrouper d’autres unités Systemd dans une chaîne de dépendances.
Par exemple, l’unité graphical.target, qui est utilisée pour lancer une session graphique, lance des services systèmes comme le gestionnaire d’affichage GNOME (gdm.service) ou le services des comptes (accounts-daemon.service) et active également l’unité multi-user.target.
De manière similaire, l’unité multi-user.target lance d’autres services système essentiels, tels que NetworkManager (NetworkManager.service) ou D-Bus (dbus.service) et active une autre unité cible nommée basic.target.
| Runlevel | Target Units | Description |
|---|---|---|
0 |
poweroff.target |
Arrête le système et l’éteint |
1 |
rescue.target |
Active un shell de secours |
2 |
multi-user.target |
Active un système multi-utilisateur sans interface graphique |
3 |
multi-user.target |
Active un système multi-utilisateur sans interface graphique |
4 |
multi-user.target |
Active un système multi-utilisateur sans interface graphique |
5 |
graphical.target |
Active un système multi-utilisateur avec interface graphique |
6 |
reboot.target |
Arrête puis redémarre le système |
La cible par défaut
Pour déterminer quelle cible est utilisée par défaut :
systemctl get-defaultCette commande recherche la cible du lien symbolique située à /etc/systemd/system/default.target et affiche le résultat.
$ systemctl get-default
graphical.targetLa commande systemctl peut également fournir la liste des cibles disponibles :
sudo systemctl list-units --type target
UNIT LOAD ACTIVE SUB DESCRIPTION
basic.target loaded active active Basic System
bluetooth.target loaded active active Bluetooth
cryptsetup.target loaded active active Encrypted Volumes
getty.target loaded active active Login Prompts
graphical.target loaded active active Graphical Interface
local-fs-pre.target loaded active active Local File Systems (Pre)
local-fs.target loaded active active Local File Systems
multi-user.target loaded active active Multi-User System
network-online.target loaded active active Network is Online
network.target loaded active active Network
nss-user-lookup.target loaded active active User and Group Name Lookups
paths.target loaded active active Paths
remote-fs.target loaded active active Remote File Systems
slices.target loaded active active Slices
sockets.target loaded active active Sockets
sound.target loaded active active Sound Card
swap.target loaded active active Swap
sysinit.target loaded active active System Initialization
timers.target loaded active active TimersPour configurer le système afin d’utiliser une cible différente par défaut :
systemctl set-default name.targetExemple :
[root]# systemctl set-default multi-user.target
rm '/etc/systemd/system/default.target'
ln -s '/usr/lib/systemd/system/multi-user.target' '/etc/systemd/system/default.target'Pour passer à une unité de cible différente dans la session actuelle :
systemctl isolate name.targetLe mode de secours ("Rescue mode") fournit un environnement simple et permet de réparer votre système dans les cas où il est impossible d’effectuer un processus de démarrage normal.
En mode de secours, le système tente de monter tous les systèmes de fichiers locaux et de lancer plusieurs services système importants, mais n’active pas d’interface réseau ou ne permet pas à d’autres d’utilisateurs de se connecter au système au même moment.
Sur CentOS7/RHEL7, le mode de secours est équivalent au mode utilisateur seul (single user mode) et requiert le mot de passe root.
Pour modifier la cible actuelle et entrer en mode de secours dans la session actuelle :
systemctl rescueLe mode d’urgence ("Emergency mode") fournit l’environnement le plus minimaliste possible et permet de réparer le système même dans des situations où le système est incapable d’entrer en mode de secours. Dans le mode d’urgence, le système monte le système de fichiers root uniquement en lecture, il ne tentera pas de monter d’autre système de fichiers locaux, n’activera pas d’interface réseau et lancera quelques services essentiels.
Pour modifier la cible actuelle et entrer en mode d’urgence dans la session actuelle :
systemctl emergencyArrêt, suspension et hibernation
La commande systemctl remplace un certain nombre de commandes de gestion de l’alimentation utilisées dans des versions précédentes :
| Ancienne commande | Nouvelle commande | Description |
|---|---|---|
halt |
systemctl halt |
Arrête le système. |
poweroff |
systemctl poweroff |
Met le système hors-tension. |
reboot |
systemctl reboot |
Redémarre le système. |
pm-suspend |
systemctl suspend |
Suspend le système. |
pm-hibernate |
systemctl hibernate |
Met le système en hibernation. |
pm-suspend-hybrid |
systemctl hybrid-sleep |
Met en hibernation et suspend le système. |
Le processus journald
Les fichiers journaux peuvent, en plus de rsyslogd, également être gérés par le démon journald qui est un composant de systemd.
Le démon journald capture les messages Syslog, les messages du journal du noyau, les messages du disque RAM initial et du début du démarrage, ainsi que les messages inscrits sur la sortie standard et la sortie d’erreur standard de tous les services, puis il les indexe et les rend disponibles à l’utilisateur.
Le format du fichier journal natif, qui est un fichier binaire structuré et indexé, améliore les recherches et permet une opération plus rapide, celui-ci stocke également des informations de métadonnées, comme l’horodatage ou les ID d’utilisateurs.
La commande journalctl
La commande journalctl permet d’afficher les fichiers journaux.
journalctlLa commande liste tous les fichiers journaux générés sur le système. La structure de cette sortie est similaire à celle utilisée dans /var/log/messages/ mais elle offre quelques améliorations :
-
la priorité des entrées est marquée visuellement ;
-
les horodatages sont convertis au fuseau horaire local de votre système ;
-
toutes les données journalisées sont affichées, y compris les journaux rotatifs ;
-
le début d’un démarrage est marqué d’une ligne spéciale.
Utiliser l’affichage continu
Avec l’affichage continu, les messages journaux sont affichés en temps réel.
journalctl -fCette commande retourne une liste des dix lignes de journal les plus récentes. L’utilitaire journalctl continue ensuite de s’exécuter et attend que de nouveaux changements se produisent pour les afficher immédiatement.
Filtrer les messages
Il est possible d’utiliser différentes méthodes de filtrage pour extraire des informations qui correspondent aux différents besoins. Les messages journaux sont souvent utilisés pour suivre des comportements erronés sur le système. Pour afficher les entrées avec une priorité sélectionnée ou plus élevée :
journalctl -p priorityIl faut remplacer priority par l’un des mots-clés suivants (ou par un chiffre) :
-
debug (7),
-
info (6),
-
notice (5),
-
warning (4),
-
err (3),
-
crit (2),
-
alert (1),
-
et emerg (0).
Gestion des tâches
Généralités
La planification des tâches est gérée avec l’utilitaire cron. Il permet l’exécution périodique des tâches.
Il est réservé à l’administrateur et sous réserve aux utilisateurs et n’utilise qu’une commande : crontab.
Le service cron sert notamment pour :
-
Les opérations d’administration répétitives ;
-
Les sauvegardes ;
-
La surveillance de l’activité du système ;
-
L’exécution de programme.
crontab est le diminutif de chrono table : table de planification.
|
Pour mettre en place une planification, il faut que le système soit à l’heure. |
Fonctionnement du service
Le fonctionnement du service cron est assuré par un démon crond présent en mémoire.
Pour vérifier son statut :
[root]# service crond status|
Si le démon crond n’est pas en cours de fonctionnement, il faudra l’initialiser manuellement et/ou automatiquement au démarrage. En effet, même si des taches sont planifiées, elles ne seront pas lancées. |
Initialisation du démon crond en manuel :
Depuis l’arborescence /etc/rc.d/init.d :
[root]# ./crond {status|start|restart|stop}Avec la commande service :
[root]# service crond {status|start|restart|stop}Initialisation du démon crond au démarrage :
Lors du chargement du système, il est lancé dans les niveaux d’exécution 2 à 5.
[root]# chkconfig --list crond
crond 0:arrêt 1:arrêt 2:marche 3:marche 4:marche 5:marche 6:arrêtLa sécurité
Afin de mettre en oeuvre une planification, un utilisateur doit avoir la permission de se servir du service cron.
Cette permission varie suivant les informations contenues dans les fichiers ci-dessous :
-
/etc/cron.allow
-
/etc/cron.deny
|
Si aucun des deux fichiers n’est présent, tous les utilisateurs peuvent utiliser cron. |
Autorisations
/etc/cron.allow
Seuls les utilisateurs contenus dans ce fichier sont autorisés à utiliser cron.
S’il est vide, aucun utilisateur ne peut utiliser cron.
|
Si cron.allow est présent, cron.deny est ignoré. |
/etc/cron.deny
Les utilisateurs contenus dans ce fichier ne sont pas autorisés à utiliser cron.
S’il est vide, tous les utilisateurs peuvent utiliser cron.
Autoriser un utilisateur
Seul user1 pourra utiliser cron
[root]# vi /etc/cron.allow
user1Interdire un utilisateur
Seul user2 ne pourra pas utiliser cron
[root]# vi /etc/cron.deny
user2cron.allow ne doit pas être présent.
La planification des tâches
Lorsqu’un utilisateur planifie une tâche, un fichier portant son nom est créé sous /var/spool/cron/.
Ce fichier contient toutes les informations permettant au démon crond de savoir quelle commande ou quel programme lancer et à quel moment le faire (heure, minute, jour …).
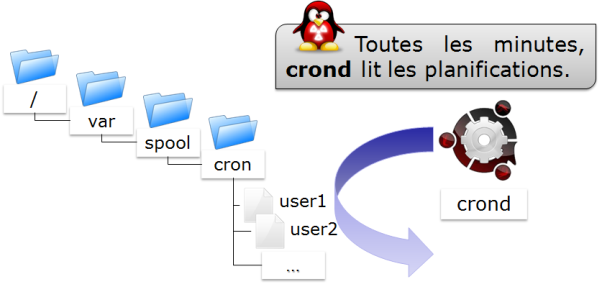
Commande crontab
La commande crontab permet de gérer le fichier de planification.
crontab [-u utilisateur] [-e | -l | -r]Exemple :
[root]# crontab –u user1 –e| Option | Description |
|---|---|
-e |
Edite le fichier de planification avec vi |
-l |
Affiche le contenu du fichier de planification |
-u |
Nom de l’utilisateur dont le ficher de planification doit être manipulé |
-r |
Efface le fichier de planification |
|
crontab sans option efface l’ancien fichier de planification et attend que l’utilisateur rentre de nouvelles lignes. Il faut taper [ctrl] + [d] pour quitter ce mode d’édition. Seul root peut utiliser l’option -u utilisateur pour gérer le fichier de planification d’un autre utilisateur. L’exemple proposé ci-dessus permet à root de planifier une tâche pour l’utilisateur user1. |
Intérêts de la planification
Les intérêts de la planification sont multiples et notamment :
-
Modifications des fichiers de planification prises en compte immédiatement ;
-
Redémarrage inutile.
En revanche, il faut faire attention aux points suivants :
-
Le programme doit être autonome ;
-
Prévoir des redirections (stdin, stdout, stderr) ;
-
Il n’est pas pertinent de lancer des commandes faisant appel à des demandes d’entrée/sortie sur un terminal.
|
Il faut bien comprendre que le but de la planification est d’effectuer des tâches de façon automatique, donc sans avoir besoin d’une intervention externe. |
Le fichier de planification
Le fichier de planification est structuré est respecte les règles suivantes.
-
Chaque ligne de ce fichier correspond à une planification ;
-
Chaque ligne comporte six champs, 5 pour le temps et 1 pour la commande ;
-
Chaque champs est séparé par un espace ou une tabulation ;
-
Chaque ligne se termine par un retour chariot ;
-
Un # en début de ligne commente celle-ci.
[root]# crontab –e
10 4 1 * * /root/scripts/backup.sh
1 2 3 4 5 6| Champ | Description | Détail |
|---|---|---|
1 |
Minute(s) |
De 0 à 59 |
2 |
Heure(s) |
De 0 à 23 |
3 |
Jour(s) du mois |
De 1 à 31 |
4 |
Mois de l’année |
De 1 à 12 |
5 |
Jour(s) de la semaine |
De 0 à 7 (0=7=dimanche) |
6 |
Tâche à exécuter |
Commande complète ou script |
|
Les tâches à exécuter doivent utiliser des chemins absolus et si possible utiliser des redirections. |
Afin de simplifier la notation pour la définition du temps, il est conseillé d’utiliser les symboles spéciaux.
| Métacaractère | Description |
|---|---|
* |
Toutes les valeurs possibles du champs |
- |
Indique un intervalle de valeurs |
, |
Indique une liste de valeurs |
/ |
Définit un pas |
Exemples :
Script exécuté le 15 avril à 10h25 :
25 10 15 04 * /root/scripts/script > /log/…Exécution à 11h puis à 16h tous les jours :
00 11,16 * * * /root/scripts/script > /log/…Exécution toutes les heures de 11h à 16h tous les jours :
00 11-16 * * * /root/scripts/script > /log/…Exécution toutes les 10 minutes aux heures de travail :
*/10 8-17 * * 1-5 /root/scripts/script > /log/…Processus d’exécution d’une tâche
Un utilisateur, Patux, veut éditer son fichier de planification :
1 ) crond vérifie s’il est autorisé (/etc/cron.allow et /etc/cron.deny ).
2 ) Si c’est le cas, il accède à son fichier de planification ( /var/spool/cron/Pierre ).
Toutes les minutes crond lit les fichiers de planification.
3 ) Il y exécute les tâches planifiées.
4 ) Il rend compte systématiquement dans un fichier journal ( /var/log/cron ).
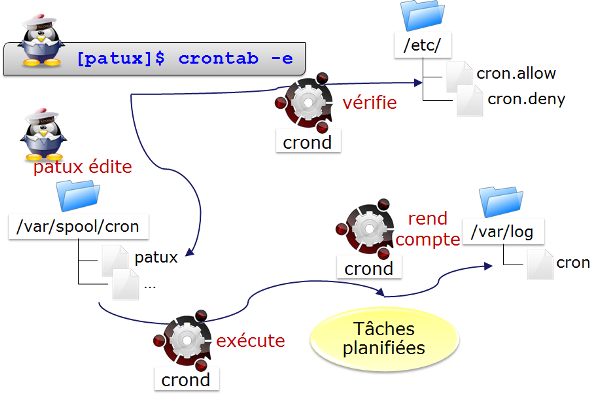
Mise en oeuvre du réseau
Généralités
Pour illustrer ce cours, nous allons nous appuyer sur l’architecture suivante.
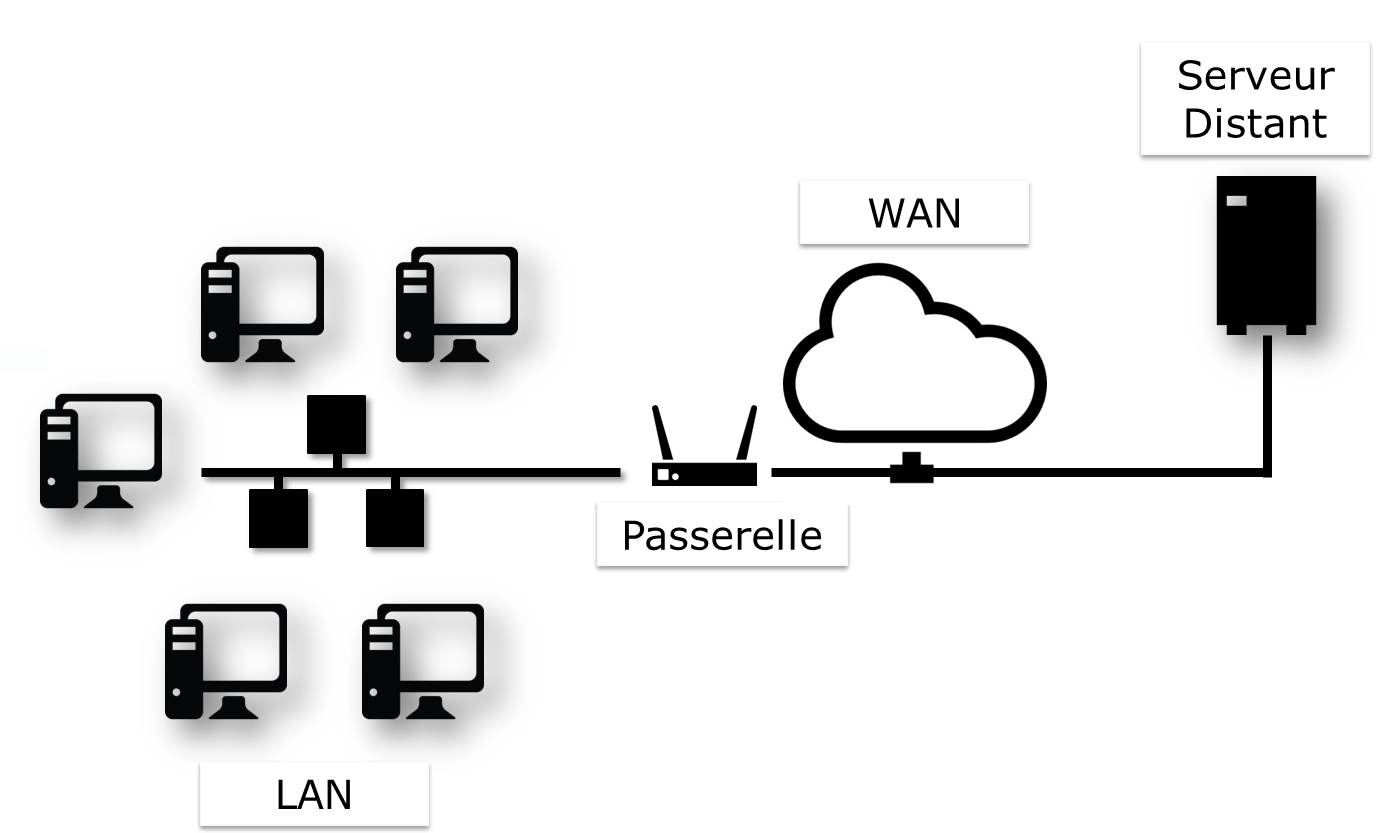
Elle nous permettra de considérer :
-
l’intégration dans un LAN (local area network, ou réseau local) ;
-
la configuration d’une passerelle pour joindre un serveur distant ;
-
la configuration d’un serveur DNS puis mettre en œuvre la résolution de nom.
Les paramètres minimum à définir propres à la machine sont :
-
le nom de la machine ;
-
l’adresse IP ;
-
le masque de sous-réseau.
Exemple :
-
pc-tux ;
-
192.168.1.10 ;
-
255.255.255.0.
La notation appelée CIDR est de plus en plus fréquente : 192.168.1.10/24
Les adresses IP servent au bon acheminement des messages. Elles sont fractionnées en deux parties :
-
la partie fixe, identifiant le réseau ;
-
l’identifiant de l’hôte dans le réseau.
Le masque de sous-réseau est un ensemble de 4 octets destiné à isoler :
-
l’adresse de réseau (NetID ou SubnetID) en effectuant un ET logique bit à bit entre l’adresse IP et le masque ;
-
l’adresse de l’hôte (HostID) en effectuant un ET logique bit à bit entre l’adresse IP et le complément du masque.
Il existe également des adresses spécifiques au sein d’un réseau, qu’il faut savoir identifier. La première adresse d’une plage ainsi que la dernière ont un rôle particulier :
-
La première adresse d’une plage est l'adresse du réseau. Elle permet d’identifier les réseaux et de router les informations d’un réseau à un autre.
-
La dernière adresse d’une plage est l'adresse de broadcast. Elle permet de faire de la diffusion à toutes les machines du réseau.
Adresse MAC / Adresse IP
Une adresse MAC est un identifiant physique inscrit en usine dans une mémoire. Elle est constituée de 6 octets souvent donnée sous forme hexadécimale (par exemple 5E:FF:56:A2:AF:15). Elle se compose de : 3 octets de l’identifiant constructeur et 3 octets du numéro de série.
|
Cette dernière affirmation est aujourd’hui un peu moins vraie avec la virtualisation. Il existe également des solutions pour changer logiciellement l’adresse MAC. |
Une adresse IP (Internet Protocol) est un numéro d’identification attribuée de façon permanente ou provisoire à chaque appareil connecté à un réseau informatique utilisant l’Internet Protocol. Une partie définit l’adresse du réseau (NetID ou SubnetID suivant le cas), l’autre partie définit l’adresse de l’hôte dans le réseau (HostID). La taille relative de chaque partie varie suivant le masque de (sous) réseau.
Une adresse IPv4 définit une adresse sur 4 octets. Le nombre d’adresse disponible étant proche de la saturation un nouveau standard a été créé, l’IPv6 définie sur 16 octets. L’IPv6 est souvent représenté par 8 groupes de 2 octets séparés par un signe deux-points. Les zéro non significatifs peuvent être omis, un ou plusieurs groupes de 4 zéros consécutifs peuvent être remplacés par un double deux-points. Les masques de sous-réseaux ont de 0 à 128 bits. (par exemple 21ac:0000:0000:0611:21e0:00ba:321b:54da/64 ou 21ac::611:21e0:ba:321b:54da/64)
Dans une adresse web ou URL (Uniform Resource Locator), une adresse ip peut être suivi de deux-points, l’adresse de port (qui indique l’application à laquelle les données sont destinées). Aussi pour éviter toute confusion dans une URL, l’adresse IPv6 s’écrit entre crochets [ ], deux-points, adresse de port.
Les adresses IP et MAC doivent être uniques sur un réseau !
|
Sous VMWare, choisir l’option « I copied it » au lancement d’une VM génère une nouvelle adresse MAC. |
Domaine DNS
Les postes clients peuvent faire partie d’un domaine DNS (Domain Name System, système de noms de domaine, par exemple mondomaine.lan).
Le nom de machine pleinement qualifié (FQDN) devient pc-tux.mondomaine.lan.
Un ensemble d’ordinateurs peut être regroupé dans un ensemble logique, permettant la résolution de nom, appelé domaine DNS. Un domaine DNS n’est pas, bien entendu, limité à un seul réseau physique.
Pour qu’un ordinateur intègre un domaine DNS, il faudra lui spécifier un suffixe DNS (ici mondomaine.lan) ainsi que des serveurs qu’il pourra interroger.
Rappel du modèle OSI
|
Aide mémoire : Pour se souvenir de l’ordre PLRTSPA, retenir la phrase suivante : Pour Les Réseaux Tu Seras Pas Augmenté. |
| Couche | Protocoles |
|---|---|
7 - Application |
POP, IMAP, SMTP, SSH, SNMP, HTTP, FTP, … |
6 - Présentation |
ASCII, MIME, … |
5 - Session |
TLS, SSL, NetBIOS, … |
4 - Transport |
TLS, SSL, TCP, UDP,… |
3 - Réseau |
IPv4, IPv6, ARP,… |
2 - Liaison |
Ethernet, WiFi, Token Ring,… |
1 - Physique |
Câbles, fibres optiques, ondes radio,… |
La couche 1 (Physique) prend en charge la transmission sur un canal de communication (Wifi, Fibre optique, câble RJ, etc.). Unité : le bit.
La couche 2 (Liaison) prend en charge la topologie du réseau (Token-ring, étoile, bus, etc.), le fractionnement des données et les erreurs de transmissions. Unité : la trame.
La couche 3 (Réseau) prend en charge la transmission de bout en bout des données (routage IP = Passerelle). Unité : le paquet.
La couche 4 (Transport) prend en charge le type de service (connecté ou non connecté), le chiffrement et le contrôle de flux. Unité : le segment ou le datagramme.
La couche 7 (Application) représente le contact avec l’utilisateur. Elle apporte les services offerts par le réseau : http, dns, ftp, imap, pop, smtp, etc.
Le nommage des interfaces
lo est l’interface “loopback” qui permet à des programmes TCP/IP de communiquer entre eux sans sortir de la machine locale. Cela permet de tester si le module « réseau » du système fonctionne bien et aussi de faire un ping localhost. Tous les paquets qui entrent par localhost ressortent par localhost. Les paquets reçus sont les paquets envoyés.
Le noyau Linux attribue des noms d’interfaces composés d’un préfixe précis selon le type. Sur des distributions Linux RHEL 6, toutes les interfaces Ethernet, par exemple, commencent par eth. Le préfixe est suivi d’un chiffre, le premier étant 0 (eth0, eth1, eth2…). Les interfaces wifi se voient attribuées un préfixe wlan.
Utiliser la commande IP
Oubliez l’ancienne commande ifconfig ! Pensez ip !
|
Commentaire à destination des administrateurs d’anciens systèmes Linux : La commande historique de gestion du réseau est ifconfig. Cette commande a tendance a être remplacée par la commande ip, déjà bien connue des administrateurs réseaux. La commande ip est la commande unique pour gérer l’adresse IP, ARP, le routage, etc. La commande ifconfig n’est plus installée par défaut sous RHEL 7. Il est important de prendre des bonnes habitudes dès maintenant. |
Le nom de machine
La commande hostname affiche ou définit le nom d’hôte du système
hostname [-f] [hostname]
| Option | Description |
|---|---|
-f |
Affiche le FQDN |
-i |
Affiche les adresses IP du système |
|
Cette commande est utilisée par différents programmes réseaux pour identifier la machine. |
Pour affecter un nom d’hôte, il est possible d’utiliser la commande hostname, mais les changements ne seront pas conservés au prochain démarrage. La commande sans argument permet d’afficher le nom de l’hôte.
Pour fixer le nom d’hôte, il faut modifier le fichier /etc/sysconfig/network :
NETWORKING=yes
HOSTNAME=stagiaire.mondomaine.lanLe script de démarrage sous RedHat consulte également le fichier /etc/hosts pour résoudre le nom d’hôte du système.
Lors du démarrage du système, Linux vient évaluer la valeur HOSTNAME du fichier /etc/sysconfig/network.
Il utilise ensuite le fichier /etc/hosts pour évaluer l’adresse IP principale du serveur et son nom d’hôte. Il en déduit le nom de domaine DNS.
Il est donc primordiale de bien renseigner ces deux fichiers avant toute configuration de services réseaux.
|
Pour savoir si cette configuration est bien faîte, les commandes hostname et hostname –f doivent répondre les bonnes valeurs attendues. |
Le fichier /etc/hosts
Le fichier /etc/hosts est une table de correspondance statique des noms d’hôtes, qui respecte le format suivant :
@IP <nom d'hôte> [alias] [# commentaire]
Exemple de fichier /etc/hosts :
127.0.0.1 localhost localhost.localdomain
::1 localhost localhost.localdomain
192.168.1.10 stagiaire.mondomaine.lan stagiaireLe fichier /etc/hosts est encore employé par le système, notamment lors du démarrage durant lequel le FQDN du système est déterminé.
|
RedHat préconise qu’au moins une ligne contenant le nom du système soit renseignée. |
Si le service DNS (Domain Name Service) n’est pas en place, vous devez renseigner tous les noms dans le fichier hosts de chacune de vos machines.
Le fichier /etc/hosts contient une ligne par entrée, comportant l’adresse IP, le FQDN, puis le nom d’hôte (dans cet ordre) et une suite d’alias (alias1 alias2 …). L’alias est une option.
Le fichier /etc/nsswitch.conf
Le Name Service Switch (NSS) permet de substituer des fichiers de configuration (par exemple /etc/passwd, /etc/group, /etc/hosts) par une ou plusieurs bases de données centralisées
Le fichier /etc/nsswitch.conf permet de configurer les bases de données du service de noms.
passwd: files
shadow: files
group: files
hosts: files dnsDans le cas présent, Linux cherchera en premier une correspondance de noms d’hôtes (ligne hosts:) dans le fichier /etc/hosts (valeur files) avant d’interroger le DNS (valeur dns)! Ce comportement peut simplement être changé en éditant le fichier /etc/nsswitch.conf.
Bien évidemment, il est possible d’imaginer interroger un serveur LDAP, MySQL ou autre en configurant le service de noms pour répondre aux requêtes du systèmes sur les hosts, les utilisateurs, les groupes, etc.
La résolution du service de noms peut être testée avec la commande getent que nous verrons plus loin dans ce cours.
Le fichier /etc/resolv.conf
Le fichier /etc/resolv.conf contient la configuration de la résolution de nom DNS.
#Generated by NetworkManager
domain mondomaine.lan
search mondomaine.lan
nameserver 192.168.1.254|
Ce fichier est historique. Il n’est plus renseigné directement ! |
Les nouvelles générations de distributions ont généralement intégré le service NetworkManager. Ce service permet de gérer plus efficacement la configuration, que ce soit en mode graphique ou console.
Il permet notamment de configurer les serveurs DNS depuis le fichier de configuration d’une interface réseau. Il se charge alors de renseigner dynamiquement le fichier /etc/resolv.conf qui ne devrait jamais être édité directement, sous peine de perdre les changements de configuration au prochain démarrage du service réseau.
La commande ip
La commande ip du paquet iproute2 permet de configurer une interface et sa table routage.
Afficher les interfaces :
[root]# ip linkAfficher les informations des interfaces :
[root]# ip addr showAfficher les informations d’une interface :
[root]# ip addr show eth0Afficher la table ARP:
[root]# ip neighToutes les commandes historiques de gestion du réseau ont été regroupées sous la commande IP, bien connue des administrateurs réseaux.
Configuration DHCP
Le protocole DHCP (Dynamic Host Control Protocol) permet d’obtenir via le réseau une configuration IP complète. C’est le mode de configuration par défaut d’une interface réseau sous RedHat, ce qui explique qu’un système branché sur le réseau d’une box internet puisse fonctionner sans configuration supplémentaire.
La configuration des interfaces sous RHEL 6 se fait dans le dossier /etc/sysconfig/network-scripts/.
Pour chaque interface ethernet, un fichier ifcfg-ethX permet de configurer l’interface associée.
DEVICE=eth0
ONBOOT=yes
BOOTPROTO=dhcp
HWADDR=00:0c:29:96:32:e3-
Nom de l’interface : (doit être dans le nom du fichier)
DEVICE=eth0-
Démarrer automatiquement l’interface :
ONBOOT=yes-
Effectuer une requête DHCP au démarrage de l’interface :
BOOTPROTO=dhcp-
Spécifier l’adresse MAC (facultatif mais utile lorsqu’il y a plusieurs interfaces) :
HWADDR=00:0c:29:96:32:e3|
Si NetworkManager est installé, les modifications sont prises en compte automatiquement. Sinon, il faut redémarrer le service réseau. |
Redémarrer le service réseau :
[root]# service network restartet sous RHEL 7 :
[root]# systemctl restart networkConfiguration statique
La configuration statique nécessite à minima :
DEVICE=eth0
ONBOOT=yes
BOOTPROTO=none
IPADDR=192.168.1.10
NETMASK=255.255.255.0-
Ne pas utiliser DHCP = configuration statique
BOOTPROTO=none-
Adresse IP :
IPADDR=192.168.1.10-
Masque de sous-réseau :
NETMASK=255.255.255.0-
Le masque peut être spécifié avec un préfixe :
PREFIX=24|
Il faut utiliser NETMASK OU PREFIX - Pas les deux ! |
|
Pensez à redémarrer le service network ! |
Routage
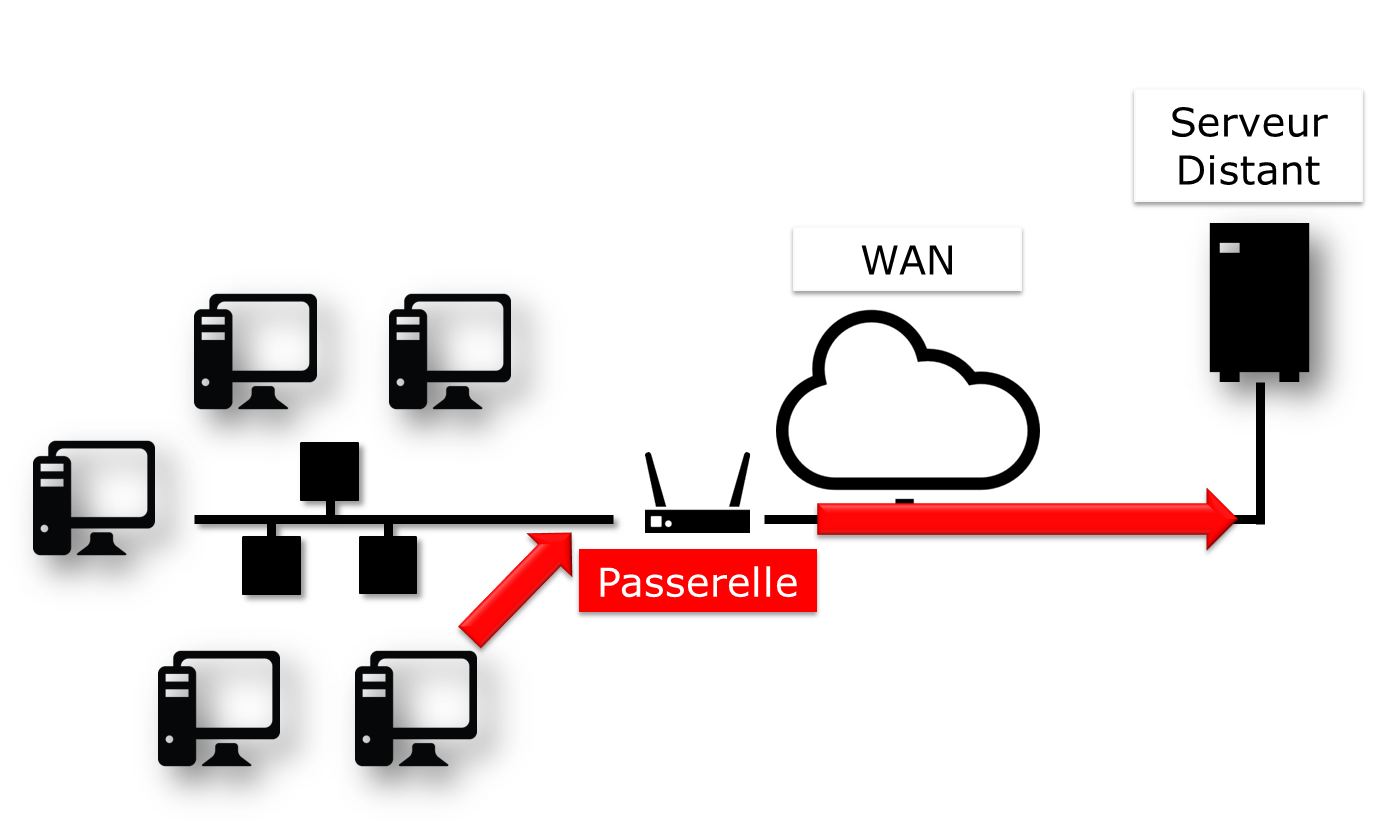
DEVICE=eth0
ONBOOT=yes
BOOTPROTO=none
HWADDR=00:0c:29:96:32:e3
IPADDR=192.168.1.10
NETMASK=255.255.255.0
GATEWAY=192.168.1.254|
Pensez à redémarrer le service network ! |
[root]# ip route show
192.168.1.0/24 dev eth0 […] src 192.168.1.10 metric 1
default via 192.168.1.254 dev eth0 proto staticIl est judicieux de savoir lire une table de routage, surtout dans un environnement disposant de plusieurs interfaces réseaux.
-
Dans l’exemple présenté, le réseau 192.168.1.0/24 est directement accessible depuis le périphérique eth0, il y a donc une métrique à 1 (ne traverse pas de routeur).
-
Tous les autres réseaux que le réseau précédent seront joignables, toujours depuis le périphérique eth0, mais cette fois-ci les paquets seront adressés à une passerelle 192.168.1.254. Le protocole de routage est un protocole statique (bien qu’il soit possible d’ajouter un protocole de routage dynamique sous Linux).
Résolution de noms
Un système a besoin de résoudre :
-
des FQDN en adresses IP
www.free.fr = 212.27.48.10-
des adresses IP en noms
212.27.48.10 = www.free.fr-
ou d’obtenir des informations sur une zone :
MX de free.fr = 10 mx1.free.fr + 20 mx2.free.frDEVICE=eth0
ONBOOT=yes
BOOTPROTO=none
HWADDR=00:0c:29:96:32:e3
IPADDR=192.168.1.10
NETMASK=255.255.255.0
GATEWAY=192.168.1.254
DNS1=172.16.1.2
DNS2=172.16.1.3
DOMAIN=mondomaine.lanDans ce cas, pour joindre les DNS, il faut passer par la passerelle.
#Generated by NetworkManager
domain mondomaine.lan
search mondomaine.lan
nameserver 172.16.1.2
nameserver 172.16.1.3Le fichier a bien été mis à jour par NetworkManager.
Dépannage
La commande ping permet d’envoyer des datagrammes à une autre machine et attend une réponse.
C’est la commande de base pour tester le réseau car elle vérifie la connectivité entre votre interface réseau et une autre.
ping [-c numérique] destinationL’option -c (count) permet de stopper la commande au bout du décompte exprimé en seconde.
Exemple :
[root]# ping –c 4 localhost|
Validez la connectivité du plus proche au plus lointain |
1) Valider la couche logicielle TCP/IP
[root]# ping localhost« Pinguer » la boucle interne ne permet pas de détecter une panne matérielle sur l’interface réseau. Elle permet simplement de déterminer si la configuration logicielle IP est correcte.
2) Valider la carte réseau
[root]# ping 192.168.1.10Pour déterminer que la carte réseau est fonctionnelle, il faut maintenant faire un « ping » de son adresse IP. La carte réseau, si le câble réseau n’est pas connecté, devrait être dans un état « down ».
Si le ping ne fonctionne pas, vérifier dans un premier temps le câble réseau vers votre le commutateur réseau et remonter l’interface (voir la commande if up), puis vérifiez l’interface elle-même.
3) Valider la connectivité de la passerelle
[root]# ping 192.168.1.2544) Valider la connectivité d’un serveur distant
[root]# ping 172.16.1.25) Valider le service DNS
[root]# ping www.free.frLa commande dig
La commande dig (dig : en français 'miner', chercher en profondeur) permet d’interroger le serveur DNS.
dig [-t type] [+short] [name]Exemples :
[root]# dig +short www.formatux.fr
46.19.120.31
[root]# dig –t MX +short formatux.fr
10 smtp.formatux.fr.La commande DIG permet d’interroger les serveurs DNS. Elle est par défaut très verbeuse, mais ce comportement peut être changé grâce à l’option +short.
Il est également possible de spécifier un type d’enregistrement DNS à résoudre, comme par exemple un type MX pour obtenir des renseignements sur les serveurs de messagerie d’un domaine.
Pour plus d’informations à ce sujet, voir le cours « DNS avec Bind9 »
La commande getent
La commande getent (get entry) permet d’obtenir une entrée de NSSwitch (hosts + dns)
getent hosts nameExemple :
[root]# getent hosts www.formatux.fr
46.19.120.31 www.formatux.frInterroger uniquement un serveur DNS peut renvoyer un résultat erroné qui ne prendrait pas en compte le contenu d’un fichier hosts, bien que ce cas de figure devrait être rare aujourd’hui.
Pour prendre en compte également le fichier /etc/hosts, il faut interroger le service de noms NSSwitch, qui se chargera d’une éventuelle résolution DNS.
La commande ipcalc
La commande ipcalc (ip calcul) permet de calculer l’adresse d’un réseau ou d’un broadcast depuis une adresse IP et un masque.
ipcalc [options] IP <netmask>Exemple :
[root]# ipcalc –b 172.16.66.203 255.255.240.0
BROADCAST=172.16.79.255|
Cette commande est intéressante suivie d’une redirection pour renseigner automatiquement les fichiers de configuration de vos interfaces : |
| Option | Description |
|---|---|
-b |
Affiche l’adresse de broadcast. |
-n |
Affiche l’adresse du réseau et du masque. |
ipcalc permet de calculer simplement les informations IP d’un hôte. Les diverses options indiquent quelles informations ipcalc doit afficher sur la sortie standard. Des options multiples peuvent être indiquées. Une adresse IP sur laquelle opérer doit être spécifiée. La plupart des opérations nécessitent aussi un masque réseau ou un préfixe CIDR.
| Option courte | Option longue | Description |
|---|---|---|
-b |
--broadcast |
Affiche l’adresse de diffusion de l’adresse IP donnée et du masque réseau. |
-h |
--hostname |
Affiche le nom d’hôte de l’adresse IP donnée via le DNS. |
-n |
--netmask |
Calcule le masque réseau de l’adresse IP donnée. Suppose que l’adresse IP fait partie d’un réseau de classe A, B, ou C complet. De nombreux réseaux n’utilisent pas les masques réseau par défaut, dans ce cas une valeur incorrecte sera retournée. |
-p |
--prefix |
Indique le préfixe de l’adresse masque/IP. |
-n |
--network |
Indique l’adresse réseau de l’adresse IP et du masque donné. |
-s |
--silent |
N’affiche jamais aucun message d’erreur. |
La commande ss
La commande ss (socket statistics) affiche les ports en écoute sur le réseau
ss [-tuna]Exemple :
[root]# ss –tuna
tcp LISTEN 0 128 *:22 *:*Les commande ss et netstat (à suivre) vont se révéler très importantes pour la suite de votre cursus Linux.
Lors de la mise en œuvre des services réseaux, il est très fréquent de vérifier avec l’une de ces deux commandes que le service est bien en écoute sur les ports attendus.
La commande netstat
La commande netstat (network statistics) affiche les ports en écoute sur le réseau
netstat -tapnExemple :
[root]# netstat –tapn
tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN 2161/sshdLes conflits d’adresses IP ou d’adresses MAC
Un défaut de configuration peut amener plusieurs interfaces à utiliser la même adresse IP. Cette situation peut se produire lorsqu’un réseau dispose de plusieurs serveurs DHCP ou lorsque la même adresse IP est manuellement assignée plusieurs fois.
Lorsque le réseau fonctionne mal, que des dysfonctionnements ont lieu, et qu’un conflit d’adresses IP pourrait en être à l’origine, il est possible d’utiliser le logiciel arp-scan (nécessite le dépôt EPEL) :
$ yum install arp-scanExemple :
$ arp-scan -I eth0 -l
172.16.1.104 00:01:02:03:04:05 3COM CORPORATION
172.16.1.107 00:0c:29:1b:eb:97 VMware, Inc.
172.16.1.250 00:26:ab:b1:b7:f6 (Unknown)
172.16.1.252 00:50:56:a9:6a:ed VMWare, Inc.
172.16.1.253 00:50:56:b6:78:ec VMWare, Inc.
172.16.1.253 00:50:56:b6:78:ec VMWare, Inc. (DUP: 2)
172.16.1.253 00:50:56:b6:78:ec VMWare, Inc. (DUP: 3)
172.16.1.253 00:50:56:b6:78:ec VMWare, Inc. (DUP: 4)
172.16.1.232 88:51:fb:5e:fa:b3 (Unknown) (DUP: 2)|
Comme l’exemple ci-dessus le démontre, il est également possible d’avoir des conflits d’adresses MAC ! Ces problématiques sont apportées par les technologies de virtualisation et la recopie de machines virtuelles. |
Configuration à chaud
La commande ip peut ajouter à chaud une adresse IP à une interface
ip addr add @IP dev DEVICEExemple :
[root]# ip addr add 192.168.2.10 dev eth1La commande ip permet d’activer ou désactiver une interface :
ip link set DEVICE up
ip link set DEVICE downExemple :
[root]# ip link set eth1 up
[root]# ip link set eth1 downLa commande ip permet d’ajouter une route :
ip route add [default|netaddr] via @IP [dev device]Exemple :
[root]# ip route add default via 192.168.1.254
[root]# ip route add 192.168.100.0/24 via 192.168.2.254 dev eth1En résumé
Les fichiers mis en oeuvre durant ce chapitre sont :
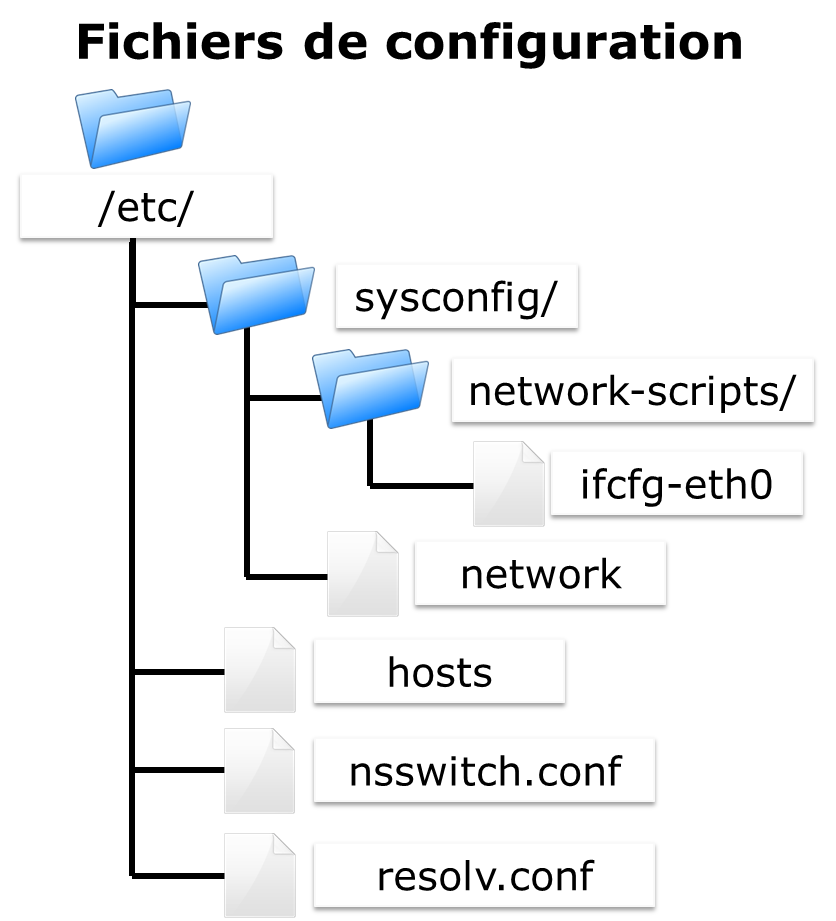
Une configuration complète d’une interface pourrait être celle-ci :
DEVICE=eth0
ONBOOT=yes
BOOTPROTO=none
HWADDR=00:0c:29:96:32:e3
IPADDR=192.168.1.10
NETMASK=255.255.255.0
GATEWAY=192.168.1.254
DNS1=172.16.1.1
DNS2=172.16.1.2
DOMAIN=formatux.frLa méthode de dépannage doit aller du plus proche au plus lointain :
-
ping localhost (test logiciel)
-
ping adresse-IP (test matériel)
-
ping passerelle (test connectivité)
-
ping serveur-distant (test routage)
-
Interrogation DNS (dig ou ping)
Gestion des logiciels
Généralités
Sur un système Linux, il est possible d’installer un logiciel de deux façons :
-
en utilisant un paquet d’installation ;
-
en compilant les fichiers sources.
Le paquet : Il s’agit d’un unique fichier comprenant toutes les données utiles à l’installation du programme. Il peut être exécuté directement sur le système à partir d’un dépôt logiciel.
Les fichiers sources : Certains logiciels ne sont pas fournis dans des paquets prêts à être installés mais via une archive contenant les fichiers sources. Charge à l’administrateur de préparer ces fichiers et de les compiler pour installer le programme.
RPM : RedHat Package Manager
RPM (RedHat Package Manager) est un système de gestion des logiciels. Il est possible d’installer, de désinstaller, de mettre à jour ou de vérifier des logiciels contenus dans des paquets.
RPM est le format utilisé par toutes les distributions à base RedHat (Fedora, CentOS, SuSe, Mandriva, …). Son équivalent dans le monde de Debian est DPKG (Debian Package).
Le nom d’un paquet RPM répond à une nomenclature précise :
Commande rpm
La commande rpm permet d’installer un paquet.
rpm [-i][-U] paquet.rpm [-e] paquetExemple :
[root]# rpm -ivh paquet.rpm| Option | Description |
|---|---|
-i paquet.rpm |
Installe le paquet. |
-U paquet.rpm |
Met à jour un paquet déjà installé. |
-e paquet.rpm |
Désinstalle le paquet. |
-h |
Affiche une barre de progression. |
-v |
Informe sur l’avancement de l’opération. |
--test |
Teste la commande sans l’exécuter. |
La commande rpm permet aussi d’interroger la base de données des paquets du système en ajoutant l’option -q.
Il est possible d’exécuter plusieurs types de requêtes pour obtenir différentes informations sur les paquets installés. La base de donnée RPM se trouve dans le répertoire /var/lib/rpm .
Exemple :
[root]# rpm -qaCette commande interroge tous les paquets installés sur le système.
rpm -q [-a][-i][-l] paquet [-f] fichierExemple :
[root]# rpm -qil paquet
[root]# rpm -qf /chemin/fichier| Option | Description |
|---|---|
-a |
Liste tous les paquets installés sur le système. |
-i paquet |
Affiche les informations du paquet. |
-l paquet |
Liste les fichiers contenus dans le paquet. |
-f |
Affiche le nom du paquet contenant le fichier précisé. |
--last |
La liste des paquets est donnée par date d’installation (les derniers paquetages installés apparaissent en premier). |
|
Après l’option -q, le nom du paquet doit être exact. Les métacaractères ne sont pas gérés. |
|
Il est cependant possible de lister tous les paquets installés et de filtrer avec la commande grep. |
Exemple : lister les derniers paquets installés :
sudo rpm -qa --last | head
kernel-devel-3.10.0-514.21.2.el7.x86_64 mar. 27 juin 2017 14:52:21 CEST
webmin-1.850-1.noarch mar. 27 juin 2017 14:51:59 CEST
kernel-3.10.0-514.21.2.el7.x86_64 mar. 27 juin 2017 14:51:32 CEST
sudo-1.8.6p7-23.el7_3.x86_64 mar. 27 juin 2017 14:51:23 CEST
python-perf-3.10.0-514.21.2.el7.x86_64 mar. 27 juin 2017 14:51:22 CEST
kernel-tools-3.10.0-514.21.2.el7.x86_64 mar. 27 juin 2017 14:51:22 CEST
glibc-headers-2.17-157.el7_3.4.x86_64 mar. 27 juin 2017 14:51:22 CEST
glibc-devel-2.17-157.el7_3.4.x86_64 mar. 27 juin 2017 14:51:22 CEST
kernel-headers-3.10.0-514.21.2.el7.x86_64 mar. 27 juin 2017 14:51:21 CEST
kernel-tools-libs-3.10.0-514.21.2.el7.x86_64 mar. 27 juin 2017 14:51:20 CESTExemple : lister l’historique d’installation du kernel :
sudo rpm -qa --last kernel
kernel-3.10.0-514.21.2.el7.x86_64 mar. 27 juin 2017 14:51:32 CEST
kernel-3.10.0-514.21.1.el7.x86_64 mar. 20 juin 2017 10:31:38 CEST
kernel-3.10.0-514.16.1.el7.x86_64 lun. 17 avril 2017 09:41:52 CEST
kernel-3.10.0-514.10.2.el7.x86_64 lun. 27 mars 2017 07:07:10 CEST
kernel-3.10.0-514.6.1.el7.x86_64 dim. 05 févr. 2017 18:40:50 CETYUM : Yellow dog Updater Modified
YUM est un gestionnaire de paquets logiciels. Il fonctionne avec des paquets RPM regroupés dans un dépôt (un répertoire de stockage des paquets) local ou distant.
La commande yum permet la gestion des paquets en comparant ceux installés sur le système à ceux présents dans les dépôts définis sur le serveur. Elle permet aussi d’installer automatiquement les dépendances, si elles sont également présentes dans les dépôts.
YUM est le gestionnaire utilisé par de nombreuses distributions à base RedHat (Fedora, CentOS, …). Son équivalent dans le monde Debian est APT (Advanced Packaging Tool).
Commande yum
La commande yum permet d’installer un paquet en ne spécifiant que le nom court.
yum [install][remove][list all][search][info] paquetExemple :
[root]# yum install treeSeul le nom court du paquet est nécessaire.
| Option | Description |
|---|---|
install |
Installe le paquet. |
remove |
Désinstalle le paquet. |
list all |
Liste les paquets déjà présents dans le dépôt. |
search |
Recherche un paquet dans le dépôt. |
provides */nom_cmde |
Recherche une commande. |
info |
Affiche les informations du paquet. |
La commande yum list liste tous les paquets installés sur le système et présents dans le dépôt. Elle accepte plusieurs paramètres :
| Paramètre | Description |
|---|---|
all |
Liste les paquets installés puis ceux disponible sur les dépôts. |
available |
Liste uniquement les paquets disponible pour installation. |
updates |
Liste les paquets pouvant être mis à jour. |
obsoletes |
Liste les paquets rendus obsolètes par des versions supérieures disponibles. |
recent |
Liste les derniers paquets ajoutés au dépôt. |
Exemple de recherche de la commande semanage :
[root]# yum provides */semanageFonctionnement de YUM
Sur un poste client, le gestionnaire YUM s’appuie sur un ou plusieurs fichiers de configuration afin de cibler les dépôts contenant les paquets RPM.
Ces fichiers sont situés dans /etc/yum.repos.d/ et se terminent obligatoirement par .repo afin d’être exploités par YUM.
Exemple :
/etc/yum.repos.d/MonDepotLocal.repoChaque fichier .repo se constitue au minimum des informations suivantes, une directive par ligne. Exemple:
[DepotLocal] #Nom court du dépôt
name=Mon dépôt local #Nom détaillé
baseurl=http://....... ou file:///...... #Adresse http ou local
enabled=1 #Activation =1, ou non activé =0"
gpgcheck=1 #Dépôt demandant une signature
gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-CentOS-6 #Chemin de la clef publique GPGPar défaut, la directive enabled est absente ce qui signifie que le dépôt est activé. Pour désactiver un dépôt, il faut spécifier la directive enabled=0.
Gérer son dépôt
La création d’un dépôt permet de disposer de sa propre banque de paquets. Celle-ci peut-être disponible par exemple par point de montage ou mise à disposition sur un serveur web.
Les étapes de la création d’un dépôt sur un serveur sont les suivantes :
-
Créer un répertoire qui va accueillir tous les paquets rpm ;
[root]# mkdir /MonDepot-
Copier tous les paquets rpm nécessaires dans ce dossier ;
[root]# cp ../*.rpm /MonDepot/-
Créer la structure et générer le dépôt à l’aide de la commande createrepo ;
[root]# createrepo /MonDepot-
Configurer les fichiers .repo des clients afin qu’ils puissent installer les paquets depuis ce serveur (réinitialiser le cache des clients si besoin avec yum clean all).
Le dépôt EPEL
Le dépôt EPEL (Extra Packages for Enterprise Linux) est un dépôt contenant des paquets logiciels supplémentaires pour Entreprise Linux, ce qui inclut RedHat Entreprise Linux (RHEL), CentOS, etc.
Installation
Télécharger et installer le rpm du dépôt :
Si vous êtes derrière le proxy internet de l’école
[root]# export http_proxy=http://10.10.10.7:8080-
Pour une CentOS 6 :
[root]# rpm -ivh http://dl.fedoraproject.org/pub/epel/6/x86_64/epel-release-6-8.noarch.rpmAprès avoir installé le paquet RPM du dépôt :
[root]# yum updateCommandes avancées pour utilisateurs Linux
La commande uniq
La commande uniq est une commande, utilisée avec la commande sort très puissante, notamment pour l’analyse de fichiers de logs. Elle permet de trier et d’afficher des entrées en supprimant les doublons.
Pour illustre le fonctionnement de la commande uniq, utilisons un fichier prenoms.txt contenant une liste de prénoms :
antoine
xavier
patrick
xavier
antoine
antoine|
uniq réclame que le fichier d’entrée soit trié car il ne compare que les lignes consécutives. |
Sans argument, la commande uniq ne va pas afficher les lignes identiques qui se suivent du fichier prenoms.txt :
$ sort prenoms.txt | uniq
antoine
patrick
xavierPour n’afficher que les lignes n’apparaissant qu’une seule fois, il faut utiliser l’option -u :
$ sort prenoms.txt | uniq -u
patrickA l’inverse, pour n’afficher que les lignes apparaissant au moins deux fois dans le fichier, il faut utiliser l’option -d :
$ sort prenoms.txt | uniq -d
antoine
xavierPour simplement supprimer les lignes qui n’apparaissent qu’une seule fois, il faut utiliser l’option -D :
$ sort prenoms.txt | uniq -D
antoine
antoine
antoine
xavier
xavierEnfin, pour compter le nombre d’occurrences de chaque ligne, il faut utiliser l’option -c :
$ sort prenoms.txt | uniq -c
3 antoine
1 patrick
2 xavier$ sort prenoms.txt | uniq -cd
3 antoine
2 xavierLa commande xargs
La commande xargs permet la construction et l’exécution de lignes de commandes à partir de l’entrée standard.
La commande xargs lit des arguments délimités par des blancs ou par des sauts de ligne depuis l’entrée standard, et exécute une ou plusieurs fois la commande (/bin/echo par défaut) en utilisant les arguments initiaux suivis des arguments lus depuis l’entrée standard.
Un premier exemple le plus simple possible serait le suivant :
$ xargs
utilisation
de
xargs
<CTRL+D>
utilisation de xargsLa commande xargs attend une saisie depuis l’entrée standard stdin. Trois lignes sont saisies. La fin de la saisie utilisateur est spécifiée à xargs par la séquence de touches <CTRL+D>. Xargs exécute alors la commande par défaut echo suivi des trois arguments correspondants à la saisie utilisateur, soit :
$ echo "utilisation" "de" "xargs"
utilisation de xargsIl est possible de spécifier une commande à lancer par xargs.
Dans l’exemple qui suit, xargs va exécuter la commande ls -ld sur l’ensemble des dossiers qui seront spécifiés depuis l’entrée standard :
$ xargs ls -ld
/home
/tmp
/root
<CTRL+D>
drwxr-xr-x. 9 root root 4096 5 avril 11:10 /home
dr-xr-x---. 2 root root 4096 5 avril 15:52 /root
drwxrwxrwt. 3 root root 4096 6 avril 10:25 /tmpEn pratique, la commande xargs a exécuté la commande ls -ld "/home" "/tmp" "/root".
Que se passe-t-il si la commande à exécuter n’accepte pas plusieurs arguments comme c’est le cas pour la commande find ?
$ xargs find /var/log -name
*.old
*.log
find: les chemins doivent précéder l'expression : *.logLa commande xargs a tenté d’exécuter la commande find avec plusieurs arguments derrière l’option -name, ce qui fait généré par find une erreur :
$ find /var/log -name "*.old" "*.log"
find: les chemins doivent précéder l'expression : *.logDans ce cas, il faut forcer la commande xargs à exécuter plusieurs fois (une fois par ligne saisie en entrée standard) la commande find. L’option -L suivie d’un nombre entier permet de spécifier le nombre maximal d’entrées à traiter avec la commande en une seule fois :
$ xargs -L 1 find /var/log -name
*.old
/var/log/dmesg.old
*.log
/var/log/boot.log
/var/log/anaconda.yum.log
/var/log/anaconda.storage.log
/var/log/anaconda.log
/var/log/yum.log
/var/log/audit/audit.log
/var/log/anaconda.ifcfg.log
/var/log/dracut.log
/var/log/anaconda.program.logSi nous avions voulu pouvoir spécifier sur la même ligne les deux arguments, il aurait fallut utiliser l’option -n 1 :
$ xargs -n 1 find /var/log -name
*.old *.log
/var/log/dmesg.old
/var/log/boot.log
/var/log/anaconda.yum.log
/var/log/anaconda.storage.log
/var/log/anaconda.log
/var/log/yum.log
/var/log/audit/audit.log
/var/log/anaconda.ifcfg.log
/var/log/dracut.log
/var/log/anaconda.program.logCas concret d’une sauvegarde avec un tar en fonction d’une recherche :
$ find /var/log/ -name "*.log" -mtime -1 | xargs tar cvfP /root/log.tar
$ tar tvfP /root/log.tar
-rw-r--r-- root/root 1720 2017-04-05 15:43 /var/log/boot.log
-rw------- root/root 499270 2017-04-06 11:01 /var/log/audit/audit.logLe paquet yum-utils
Le paquet yum-utils est une collection d’utilitaires de différents auteurs pour yum, qui le rendent plus simple et plus puissant à utiliser.
Voici quelques exemples d’utilisation :
-
La commande package-cleanup :
Elle permet (entre autre) la suppression des anciens noyau.
package-cleanup --oldkernels --count=1Options |
Commentaires |
--oldkernels |
Demande la suppression des anciens noyaux. |
--count=X |
Nombre de noyaux à conserver (par défaut = 2) |
-
La commande repoquery :
La commande repoquery interroge les dépots.
Exemples d’utilisation :
-
Connaître les dépendances d’un paquet non-installé :
repoquery --requires <package>-
Connaître les fichiers fournis par un paquet non-installé :
$ repoquery -l yum-utils
/etc/bash_completion.d
/etc/bash_completion.d/yum-utils.bash
/usr/bin/debuginfo-install
/usr/bin/find-repos-of-install
/usr/bin/needs-restarting
/usr/bin/package-cleanup
/usr/bin/repo-graph
/usr/bin/repo-rss
/usr/bin/repoclosure
/usr/bin/repodiff
/usr/bin/repomanage
/usr/bin/repoquery
/usr/bin/reposync
/usr/bin/repotrack
/usr/bin/show-changed-rco
/usr/bin/show-installed
/usr/bin/verifytree
/usr/bin/yum-builddep
/usr/bin/yum-config-manager
/usr/bin/yum-debug-dump
/usr/bin/yum-debug-restore
/usr/bin/yum-groups-manager
/usr/bin/yumdownloader
...-
La commande yumdownloader :
La commande yumdownloader télécharge les paquets RPM depuis les dépôts.
|
Cette commande est très pratique pour construire un dépôt local de quelques rpm ! |
Exemple : yumdownloader va télécharger le paquet rpm de repoquery ainsi que toutes ses dépendances.
$ yumdownloader --destdir /var/tmp -- resolve repoqueryOptions |
Commentaires |
--destdir |
Les paquets téléchargés seront conservés dans le dossier spécifié. |
--resolve |
Télécharge également les dépendances du paquet. |
Le paquet psmisc
Le paquet psmisc contient des utilitaires pour gérer les processus du système :
-
pstree : la commande pstree affiche les processus en cours sur le système sous forme de structure en forme d’arbre.
-
killall : la commande killall envoie un signal d’extinction à tous les procesuss identifiés par un nom.
-
fuser : la commande fuser identifie les PIDs des processus qui utilisent les fichiers ou les systèmes de fichiers spécifiés.
Exemples :
$ pstree
systemd─┬─NetworkManager───2*[{NetworkManager}]
├─agetty
├─auditd───{auditd}
├─crond
├─dbus-daemon───{dbus-daemon}
├─firewalld───{firewalld}
├─lvmetad
├─master─┬─pickup
│ └─qmgr
├─polkitd───5*[{polkitd}]
├─rsyslogd───2*[{rsyslogd}]
├─sshd───sshd───bash───pstree
├─systemd-journal
├─systemd-logind
├─systemd-udevd
└─tuned───4*[{tuned}]# killall httpdTue les processus (option -k) qui accèdent au fichier /etc/httpd/conf/httpd.conf :
# fuser -k /etc/httpd/conf/httpd.confLa commande watch
La commande watch exécute régulièrement une commande et affiche le résultat dans le terminal en plein écran.
L’option -n permet de spécifier le nombre de secondes entre chaque exécution de la commande.
|
Pour quitter la commande watch, il faut saisir les touches : <CTRL>+<C> pour tuer le processus. |
Exemples :
-
Afficher la fin du fichier /etc/passwd toutes les 5 secondes :
$ watch -n 5 tail -n 5 /etc/passwdRésultat :
Toutes les 5,0s: tail -n 5 /etc/p...
lightdm:x:620:620:Light Display Manager:/var/lib/lightdm:/usr/bin/nologin
clamav:x:64:64:Clam AntiVirus:/dev/null:/bin/false
systemd-coredump:x:994:994:systemd Core Dumper:/:/sbin/nologin
ceph:x:993:993::/run/ceph:/sbin/nologin
dnsmasq:x:992:992:dnsmasq daemon:/:/sbin/nologin-
Surveillance du nombre de fichier dans un dossier :
$ watch -n 1 'ls -l | wc -l'-
Afficher une horloge :
$ watch -t -n 1 dateMemento VI
Lancer vim ou vimtutor
vi [-c commande] [fichier]
$ vi -c "set nu" /home/stagiaire/fichier
$ vimtutorMode Commandes
| Caractères | Actions |
|---|---|
|
Déplacement d’un ou |
|
Déplacement d’un ou |
|
Déplacement d’un ou |
|
Déplacement d’un ou |
|
Déplacement à la fin de la ligne |
|
Déplacement au début de la ligne |
|
Déplacement d’un ou |
|
Déplacement d’un ou |
|
Déplacement à la dernière ligne du texte |
|
Déplacement à la ligne |
|
Déplacement à la première ligne de l’écran |
|
Déplacement à la ligne du milieu de l’écran |
|
Déplacement à la dernière ligne de l’écran |
|
Insertion de texte avant un caractère |
|
Insertion de texte après un caractère |
|
Insertion de texte au début d’une ligne |
|
Insertion de texte à la fin d’une ligne |
|
Insertion de texte avant une ligne |
|
Insertion de texte après une ligne |
|
Supprimer un ou |
|
Remplacer un caractère par un autre |
|
Remplacer plus d’un caractère par d’autres |
|
Supprimer (couper) un ou |
|
Copier un ou |
|
Coller un mot une ou |
|
Coller un mot une ou |
|
Remplacer un mot |
|
Supprimer (couper) une ou |
|
Copier une ou |
|
Coller ce qui a été copié ou supprimé une ou |
|
Coller ce qui a été copié ou supprimé une ou |
|
Supprimer (couper) du début de la ligne jusqu’au curseur |
|
Supprimer (couper) du curseur jusqu’à la fin de la ligne |
|
Copier du début de la ligne jusqu’au curseur |
|
Copier du curseur jusqu’à la fin de la ligne |
|
Supprimer (couper) le texte à partir de la ligne courante |
|
Copier le texte à partir de la ligne courante |
|
Annuler la dernière action |
|
Annuler les actions sur la ligne courante |
Mode EX
| Caractères | Actions |
|---|---|
|
Afficher la numérotation |
|
Mmasquer la numérotation |
|
Rechercher une chaîne de caractères à partir du curseur |
|
Rechercher une chaîne de caractères avant le curseur |
|
Aller à l’occurrence trouvée suivante |
|
Aller à l’occurence trouvée précédente |
|
Recherche d’un unique caractère dont les valeurs possibles sont précisées |
|
Recherche d’une chaîne débutant la ligne |
|
Recherche d’une chaîne finissant la ligne |
|
Recherche d’un ou de plusieurs caractères, quels qu’ils soient |
|
De la 1ère à la dernière ligne du texte, remplacer la chaîne recherchée par la chaîne précisée |
|
De la ligne |
|
Par défaut, seule la première occurence trouvée de chaque ligne est remplacée. Pour forcer le remplacement de chaque occurence, il faut ajouter |
|
Enregistrer le fichier |
|
Enregistrer sous un autre nom |
|
Enregistrer de la ligne |
|
Recharger le dernier enregistrement du fichier |
|
Coller le contenu d’un autre fichier après le curseur |
|
Quitter le fichier sans enregistrer |
|
Quitter le fichier et enregistrer |
Glossaire
| BASH |
Bourne Again SHell |
| BIOS |
Basic Input Output System |
| CIDR |
Classless Inter-Domain Routing |
| Daemon |
Disk And Execution MONitor |
| DHCP |
Dynamic Host Control Protocol |
| DNS |
Domain Name Service |
| FIFO |
First In First Out |
| FQDN |
Fully Qualified Domain Name |
| GNU |
Gnu is Not Unix |
| HA |
High Availability (Haute Disponibilité) |
| HTTP |
HyperText Transfer Protocol |
| ICP |
Internet Cache Protocol |
| IFS |
Internal Field Separator |
| LAN |
Local Area Network |
| LDIF |
LDAP Data Interchange Format |
| NTP |
Network Time Protocol |
| nsswitch |
Name Service Switch |
| OTP |
One Time Password |
| POSIX |
Portable Operating System Interface |
| POST |
Power On Self Test |
| RDBMS |
Relational DataBase Managed System |
| SGBD-R |
Systèmes de Gestion de Base de Données Relationnelles |
| SHELL |
En français "coquille". Á traduire par "interface système". |
| SMB |
Server Message Block |
| SMTP |
Simple Mail Tranfer Protocol |
| SSH |
Secure SHell |
| SSL |
Secure Socket Layer |
| TLS |
Transport Layer Security, un protocole de cryptographie pour sécuriser les communications IP. |
| TTL |
Time To Live |
| TTY |
teletypewriter, qui se traduit téléscripteur. C’est la console physique. |
| UEFI |
Unified Extensible Firmware Interface |